(by Bob Spurzem, Director of International Business, Mimosa Systems, and T.M. Ravi, Founder, President and CEO, Mimosa Systems. This article is reposted with permission from CSI Pune‘s newsletter, DeskTalk. The full newsletter is available here.)
In this era of worldwide electronic communication and fantastic new business applications, the amount of unstructured, electronic information generated by enterprises is exploding. This growth of unstructured information is the driving force of a significant surge in knowledge worker productivity and is creating an enormous risk for enterprises with no tools to manage it. Content Archiving is a new class of enterprise application designed for managing user-generated, unstructured electronic information. The purpose of Content Archiving is to manage unstructured information over the entire lifecycle, ensuring preservation of valuable electronic information, while providing easy access to historical information by knowledge workers. With finger-tip access to years of historical business records, workers make informed decisions driving top line revenue. Workers with legal and compliance responsibility search historical records easily in response to regulatory and litigation requests; thereby reducing legal costs and compliance risk. Using Content Archiving enterprises gain “finger-tip” access to important historical information – an important competitive advantage helping them be successful market leaders.
Unstructured Electronic Information
One of the most remarkable results of the computer era is the explosion of usergenerated electronic digital information. Using a plethora of software applications, including the widely popular Microsoft® Office® products, users generate millions of unmanaged data files. To share information with co-workers and anyone else, users attach files to email and instantly files are duplicated to unlimited numbers of users worldwide. The University of California, Berkeley School of Information Management and Systems measured the impact of electronically stored information and the results were staggering. Between the years 1992 to 2003, they estimated that total electronic information grew about 30% per year. Per user per year, this corresponds to almost 800 MB of electronic information. And the United States accounts for only 40% of the world’s new electronic information.
- Email generates about 4,000,000 terabytes of new information each year — worldwide.
- Instant messaging generates five billion messages a day (750GB), or about 274 terabytes a year.
- The World Wide Web contains about 170 terabytes of information on its surface; in volume this is seventeen times the size of the Library of Congress print collections.
This enormous growth in electronic digital information has created many unforeseen benefits. Hal R. Varian, a business professor at the University of California, Berkeley, notes that, “From 1974 to 1995, productivity in the United States grew at around 1.4 percent a year. Productivity growth accelerated to about 2.5 percent a year from 1995 to 2000. Since then, productivity has grown at a bit over 3 percent a year, with the last few years looking particularly strong. But unlike the United States, European countries have not seen the same surge in productivity growth in the last ten years. The reason for this is that United States companies are much farther up the learning curve than European companies for applying the benefits of information technology.”
Many software applications are responsible for the emergence of the electronic office place and this surge in productivity growth, but none more so than email. From its humble beginning as a simple messaging application for users of ARPANET in the early 1970’s, email has grown to become the number one enterprise application. In 2006, over 171 billion emails were being sent daily worldwide, a 26% increase over 2005 and this figure is forecasted to continue to grow 25-30% throughout the remaining decade. A new survey by Osterman Research polled 394 email users, “How important is your email system in helping you get your work done on a daily basis?” 76% reported that it is “extremely important”. The Osterman survey revealed that email users spend on average 2 hours 15 minutes each day doing something in email, but 28% users spend more than 3 hours per day using email. As confirmed by this survey and many others, email has become the most important tool for business communication and contributes significantly to user productivity.
The explosive growth in electronically stored information has created many challenges and has created a fundamental change in the way electronic digital information is accessed. Traditionally, electronic information was managed in closely guarded applications used by manufacturing, accounting and engineering and only accessed by a small number of trained professionals. These forms of electronic information are commonly referred to as structured electronic information. User-generated electronic information is quite different because it is in the hands of all workers – trained and untrained. User-generated information is commonly referred to as unstructured electronic information. Where many years of IT experience have solved the problems of managing structured information; the tools and methods necessary to manage unstructured information, for the most part, do not exist. For a typical enterprise, as much as 50% of total storage capacity is consumed by unstructured data and another 15-20% is made up of email data. The remaining 25-30% of enterprise storage is made up of structured data in enterprise databases.
Content Archiving
User-generated, unstructured electronic information is creating a chasm between IT staff whose responsibility it is to manage electronic information and knowledge workers who want to freely access current and historical electronic information. Knowledge workers desire “finger-tip” access to years of information which strains the ability of IT to provide information protection and availability, cost effectively. Compliance officers desire tools to search electronic information and preserve information for regulatory audits. And overshadowing everything is the need for information security. User-generated electronic information is often highly sensitive and requires secure access. As opposed to information that exists on the World Wide Web, electronic information that exists in organizations is meant only for authorized access.
Content Archiving represents a new class of enterprise application designed for managing user-generated unstructured electronic information in a way that addresses the needs of IT, knowledge workers and compliance officers. The nature of Content Archiving is to engage seamlessly with the applications that generate unstructured electronic information in a continuous manner for information capture, and to provide real-time end-user access for fast search and discovery. The interfaces currently used to access unstructured information (e.g. Microsoft Outlook®) are the same interfaces used by Content Archiving to provide end users with secure “finger-tip” access to volumes of electronic information.
Content Archiving handles a large variety of user-generated electronic information. Email is the dominate form of usergenerated electronic information and is included in this definition. So too are Microsoft Office files (e.g. Word, Excel, PowerPoint, etc.) and the countless other file formats such as .PDF and .HTML. Files that are commonly sent via email as attachments are included in both the context of email and as standalone files. In addition to email and files, there are a large number of information types that are not text based, and include digital telephony, digital pictures and digital movies. The growing popularity of digital pictures (.JPG), audio and voice mail files (.WAV, .WMA) and video files is paving the way for a new generation of communication applications. It is within reason that in the near future full length video recordings will be shared just as easily as Excel spreadsheets are today. All these user-generated data types fall under the definition of Content.
Content Archiving distinguishes itself from traditional data protection applications. Data protection solves the important problem of restoring electronic information, but does little more. Archiving, on the other hand, is a business intelligence application that solves problems such as providing secure access to electronic information for quick search and legal discovery; measuring how much information exists; identifying what type of data exists; locating where data exists and determining when data was last accessed. For managing unstructured electronic information, Content Archiving delivers important benefits for business intelligence and goes far beyond the simple recovery function that data protection provides. Using tools that archiving provides, knowledge users can easily search years of historical information and benefit from the business information contained within.
Information Life-Cycle Management
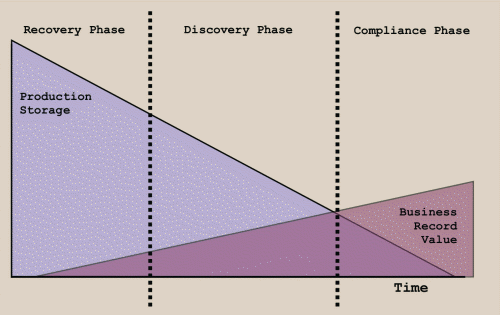
Content Archiving recognizes that electronic information must be managed over its entire life-cycle. Information that was recently created has different needs and requirements than the same information years later and should be managed accordingly. Three distinct phases exist for the management of electronic information, which are the recovery phase, discovery phase and compliance phase (see figure). It is the strategic purpose of Content Archiving to manage electronic information throughout the entire life-cycle; recognizing the value of information in the short-term for production and long-term as a record of business; while continually driving information storage levels down to reduce storage costs and preserving access to information.
During the recovery phase all production information requires equal protection and must be available for fast recovery should a logical error occur, or a hardware failure strikes the production servers. Continuous capture of information reduces the risk of losing information and supports fast disk-based recovery. The same information stores can be accessed by end users who desire easy access to restore deleted files. Content Archiving supports the recovery phase by performing as a disk-based continuous data protection application. As compared to tape-based recovery, Content Archiving can restore information more quickly and with less loss of information. It captures all information in real-time and it keeps all electronic information on cost-efficient storage where it is available for fast recovery and also can be easily accessed by end users and auditors for compliance and legal discovery. The length of the recovery phase varies according to individual needs, but is typically 6-12 months.
At a point in time, which varies by organization, the increasing volume of current and historical information puts an unmanageable strain on production servers. At the same time the value of the historical electronic information decreases because it is no longer required for recovery. This is called the discovery phase. The challenge in the discovery phase is to reduce the volume of historical information while continuing to provide easy access to all information for audits and legal discovery. Content Archiving provides automated retention and disposition policies that are intelligent and can distinguish between current information and information that has been deleted by end users. Retention rules automatically dispose of information according to policies defined by the administrator. Further reduction is achieved by removing duplicates. For audits and legal discovery, Content Archiving keeps information in a secure, indexed archive and provides powerful search tools that allow auditors quick access to all current and historical information. By avoiding using backup tapes, searches of historical information can be performed quickly and reliably; thereby reducing legal discovery costs.
Following the discovery phase, electronic information must be managed and preserved according to industry rules for records retention. This phase is called the compliance phase. Depending on the content, information may be required to be archived indefinitely. Storing information long-term is a technical challenge and costly if not done correctly. Content Archiving addresses the challenges of the compliance phase in two ways. First, Content Archiving provides tools which allow in-house experts, who know best what information is a record of business, to preserve information. Discovery tools enable auditors and legal counsel to flag electronic information as a business record or disposable. Second, Content Archiving manages electronic information in dedicated file containers. File containers are designed for long-term retention on tiered storage (e.g. tape, optical) for economic reasons and have self-contained indexes for reliable long-term access of information.
Conclusion
The explosive growth in user-generated electronic information has been a powerful benefit to knowledge worker productivity but has created many challenges to enterprises. IT staff is challenged to manage the rapidly growing information stores while keeping applications running smoothly. Compliance and legal staff are challenged to respond to regulatory audits and litigation requests to search and access electronic information quickly. Content Archiving is a new class of enterprise application designed to manage unstructured electronic information over its entire life-cycle. Adhering to architectural design rules that ensure no interruption to the source application, secure access and scalability, Content Archiving manages information upon creation during the recovery phase, the discovery phase and the compliance phase where information is preserved as a long-term business record. Content Archiving provides IT staff, end users as well compliance and legal staff with the business intelligence tools they require to manage unstructured information economically while meeting demands for quick, secure access and legal and regulatory preservation.
About the Authors
Bob Spurzem
Director International Business
Mimosa Systems
Bob has 20+ years experience in high technology product development and marketing and currently he is a Director International Business with Mimosa Systems Inc. With significant experience throughout the product life cycle, from market requirements and competitive research, through positioning, sales collateral development and product launch, he has a strong focus in bringing new products to market. Prior to this his experience includes work as a Senior Product Marketing Manager for Legato Systems and Veritas Software companies. Robert has an MBA from Santa Clara University and a Masters Degree in Biomedical Engineering from Northwestern University
T. M. Ravi
Co-founder, President, and CEO
Mimosa Systems
T. M. Ravi has had a long career with broad experience in enterprise management and storage. Before Mimosa Systems, Ravi was founder and CEO of Peakstone Corporation, a venture-financed startup providing performance management solutions for Fortune 500 companies. Previously, Ravi was vice president of marketing at Computer Associates (CA). At Computer Associates, Ravi was responsible for the core line of CA enterprise management products, including CA Unicenter, as well as the areas of application, systems and network management; software distribution; and help desk, security, and storage management. He joined CA through the $1.2 billion acquisition of Cheyenne Software, the market leader in storage management and antivirus solutions. At Cheyenne Software, Ravi was the vice president responsible for managing the company’s successful Windows NT business with products such as ARCserve backup and InocuLAN antivirus. Prior to Cheyenne, Ravi founded and was CEO of Media Blitz, a provider of Windows NT storage solutions that was acquired by Cheyenne Software. Earlier in his career, Ravi worked in Hewlett-Packard’s Information Architecture Group, where he did product planning for client/server and storage solutions.
