OpenID is a secure, customizable, user-controllable, and open mechanism to share personal information (username/password, credit card numbers, address) on the web. It will eliminate the need to enter the same information over and over again in different websites, or to remember different username/password combinations. It will be a major improvement over the current system once it gains widespread adoption. PuneTech asked Hemant Kulkarni of singleid.net to give us an introduction to OpenID, its benefits, and how it works.
Overview
In 2005, a new idea took hold and spread across the internet – OpenID. The concept is very simple – to provide users with a single unique login-password set with which they will be able to access all the different sites on the internet.
In June 2007 the OpenID Foundation was formed with the sole goal to protect OpenID. The original OpenID authentication protocol was developed by Brad Fitzpatrick, creator of popular community website LiveJournal, while working at Six Apart. The OpenID Foundation received a recent boost when the internet leaders Microsoft, Google, Yahoo! and Verisign became its corporate members.
Millions of users across the internet are already using OpenID and several thousand websites have become OpenID enabled.
Need for OpenID
The internet is fast becoming an immovable part of our everyday life. Many tasks such as booking tickets for movies, airlines, trains and buses, shopping for groceries, paying your electricity bills etc. can now be done online. Today, you can take care of all your mundane household chores at the click of a button.
When you shop online, you are usually required to use a login and a password to access these sites. This means that, as a user, you will have to maintain and remember several different login-password sets.
OpenID enables you to use just one login-password to access these different sites – making life simpler for you. With OpenID, there is no need to bother with remembering the several different logins and passwords that you may have on each different site.
Internet architecture inherently assumes that there are two key players in today’s internet world – end users who use the internet services and the websites which provide these services. It is a common misconception that OpenID-based login benefits only the end users. Of course it does. But it also has an equal value proposition for the websites that accept OpenID too.
Later, in a separate section, we will go into the details of the benefits to the websites that accept OpenID-based logins.
And before that, it is equally important to understand the few technological aspects and the various entities involved in the OpenID world.
What is OpenID
OpenID is a digital identity solution developed by the open source community. A lightweight method of identifying individuals, it uses the same framework for identifying websites. The OpenID Foundation was formed with the idea that it will act as a legal entity to manage the community and provide the infrastructure required to promote and support the use of OpenID.
In essence, an OpenID is a URL like http://yourname.SingleID.net which you can put into the login box of a website and sign in to a website. You are saved the trouble of filling in the online forms for your personal information, as the OpenID provider website shares that information with the website you are signing on to.
Adoption
As of July 2007, data shows that there are over 120 million OpenIDs on the Internet and about 10,000 sites have integrated OpenID consumer support. A few examples of OpenID promoted by different organizations are given below:
- America Online provides OpenIDs in the form “openid.aol.com/screenname”.
- Orange offeres OpenIDs to their 40 million broadband subscribers.
- VeriSign offers a secure OpenID service, which they call “Personal Identity Provider”.
- Six Apart blogging, which hosts LiveJournal and Vox, support OpenID – Vox as a provider and LiveJournal as both a provider and a relying party.
- Springnote uses OpenID as the only sign in method, requiring the user to have an OpenID when signing up.
- WordPress.com provides OpenID.
- Other services accepting OpenID as an alternative to registration include Wikitravel, photo sharing host Zooomr, linkmarking host Ma.gnolia, identity aggregator ClaimID, icon provider IconBuffet, user stylesheet repository UserStyles.org, and Basecamp and Highrise by 37signals.
- Yahoo! users can use their yahoo ids as OpenIDs.
- A complete list of sites supporting OpenID(s) is available on the OpenID Directory.
Various Entities in OpenID
Now let us look at the various entities involved in the OpenID world.
End user
This is the person who wants to assert his or her identity to a site.
Identifier
This is the URL or XRI chosen by the End User as their OpenID identifier.
Identity provider or OpenID provider
This is a service provider offering the service of registering OpenID URLs or XRIs and providing OpenID authentication (and possibly other identity services).
Note: The OpenID specifications use the term “OpenID provider” or “OP”.
Relying party
This is the site that wants to verify the end user’s identifier, who is also called a “service provider”.
Server or server-agent
This is the server that verifies the end user’s identifier. This may be the end user’s own server (such as their blog), or a server operated by an identity provider.
User-agent
This is the program (such as a browser) that the end user is using to access an identity provider or a relying party.
Consumer
This is an obsolete term for the relying party.
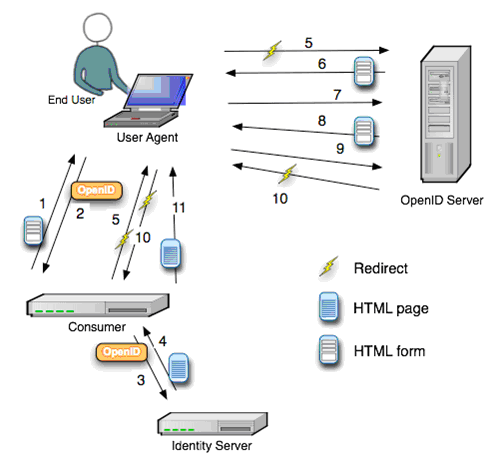
Technology in OpenID
Typically, a relying party website (like example.website.com) will display an OpenID login form somewhere on the page. Compared to a regular login form where there are fields for user name and password, the OpenID logic form only has one field for the OpenID identifier. It is often accompanied by the OpenID logo:  . This form is in turn connected to an implementation of an OpenID client library.
. This form is in turn connected to an implementation of an OpenID client library.
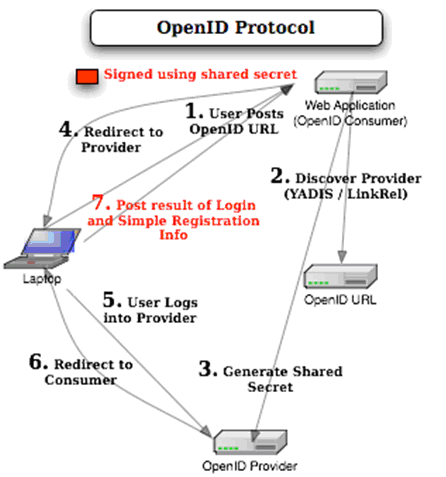
A user will have to register and have an OpenID identifier (like yourname.openid.example.org) with an OpenID provider (like openid.example.org). To login to the relying party website, the user will have to type in their OpenID identifier in the OpenID login form.
The relying party website will typically transform the OpenID identifier into a URL (like http://yourname.openid.example.org/). In OpenID 2.0, the client will thus discover the identity provider service URL by requesting the XRDS document (which is also called the Yadis document) with the content type application/xrds+xml which is available at the target URL and is always available for a target XRI.
Now, here is what happens next. The relying party and the identity provider establish a connection referenced by the associate handle. The relying party then stores this handle and redirects the user’s web browser to the identity provider to allow the authentication process.
In the next step, the OpenID identity provider prompts the user for a password, or an InfoCard and asks whether the user trusts the relying party website to receive their credentials and identity details.
The user can either agree or decline the OpenID identity provider’s request. If the user declines, the browser is redirected to the relying party with a message to that effect and the site refuses to authenticate the user. If the user accepts the request to trust the relying party website, the user’s credentials are exchanged and the browser is then redirected to the designated return page of the relying party website. Then the relying party also checks that the user’s credentials did come from the identity provider.
Once the OpenID identifier has been properly verified, the OpenID authentication is considered successful and the user is considered to be logged into the relying party website with the given identifier (like yourname.openid.example.org). The website then stores the OpenID identifier in the user’s session.
Case Study
Now let us take a simple case of Sunil, who wants to buy a Comprehensive Guide to OpenID by Raffeq Rehman, CISSP. This e-book is available only on-line at www.MyBooks.com a technology thought leader which believes in easing the end user’s on-line experience by accepting OpenID based login.
Sunil is a tech savvy individual who has already registered himself at www.singleid.net (India’s first OpenID provider) and they have provided him with his unique login identity, which is: http://sunil.sigleid.net.
The easiest entity to recognize in this purchase scenario is Sunil, the End-User. Obviously Sunil will use his web browser, which is known as the User-agent to access the MyBooks.com.
So, Sunil visits www.MyBooks.com and starts to look for the book he wants. He follows the standard procedures on this website and chooses his book and clicks the check-out link to buy this book. First thing MyBooks.com does is asks him to log-in and gives him an option of logging in with your OpenID.
Since Sunil has already registered himself with SingleId.net, they have provided him with his login-id (which is bit different). So here, www.singleid.net is the Identity Provider or OpenID provider.
Now we know that OpenID uses same method to identify individuals, which is commonly used for identifying websites and hence his identity (Identifier in OpenID context) is http://sunil.sigleid.net. Now SingleId.net part in his identity tells MyBooks.com that he has registered himself at www.singleid.net.
At this stage MyBooks.com sends him to www.singleid.net to log in. Notice that MyBooks.com does not request Sunil to login but relies on SingleID.net. And so MyBooks.com or www.MyBooks.com is the Relying Party or the Consumer. Once Sunil complete his login process which is authenticated against the Server-Agent (typically Server-Agent is nothing but your identity provider) SingleID.net sends him back to MyBooks.com and tells MyBooks.com that Sunil is the person who he says he is, and MyBooks.com can let him complete the purchase operation.
Leading Players in the OpenID World & Important Milestones
- Web developer JanRain was an early supporter of OpenID, providing OpenID software libraries and expanding its business around OpenID-based
- In March 2006, JanRain developed a Simple Registration Extension for OpenID for primitive profile-exchange
- With Verisign and Sxip Identity joining and focusing on OpenID development new standard of OpenID protocol OpenID 2.0 and OpenID Attribute Exchange extension were developed
- On January 31, 2007, computer security company Symantec announced support for OpenID in its Identity Initiative products and services. A week later, on February 6 Microsoft made a joint announcement with JanRain, Sxip, and VeriSign to collaborate on interoperability between OpenID and Microsoft’s Windows CardSpace digital identity platform, with particular focus on developing a phishing-resistant authentication solution for OpenID.
- In May 2007, information technology company Sun Microsystems began working with the OpenID community, announcing an OpenID program.
- In mid-January 2008, Yahoo! announced initial OpenID 2.0 support, both as a provider and as a relying party, releasing the service by the end of the month. In early February, Google, IBM, Microsoft, VeriSign, and Yahoo! joined the OpenID Foundation as corporate board members
OpenID: Issues in Discussion and Proposed Solutions
As is the case with any technology, there are some issues in discussion with regard to OpenID and its usability and implementation. Let us have a look at the points raised and the solutions offered:
Issue I:
Although OpenID may create a very user-friendly environment, several people have raised the issue of security. Phishing and digital identity theft are the main focus of this issue. It is claimed that OpenID may have security weaknesses which might leave user identities vulnerable to phishing.
Solution Offered:
Personal Icon: A Personal Icon is a picture that you can specify which is then presented to you in the title bar every time you visit the particular site. This aids in fighting phishing as you’ll get used to seeing the same picture at the top of the page every time you sign in. If you don’t see it, then you know that something might be up.
Issue II:
People have also criticized the login process on the grounds that having the OpenID identity provider into the authentication process adds complexity and therefore creates vulnerability in the system. This is because the ‘quality’ of such an OpenID identity provider cannot be established.
Solution Offered:
SafeSignIn: SafeSignIn is an option that users can set on their settings page that allows you to choose the option where you cannot be redirected to your OpenID provider to enter a password. You can only sign-in in provider’s login page. If you are redirected to your provider from another site, you are presented with the dialog warning you not to enter your password anywhere else.
Value Proposition
There are several benefits to using OpenID – both for the users and for the websites.
Benefits for the End User:
- You don’t have to remember multiple user IDs and passwords – just one login.
- Portability of your identity (especially if you own the domain you are delivering your identity from). This gives you better control over your identity.
Benefits for OpenID Enabled Websites:
- No more registration forms: With OpenID, websites can get rid of the clutter of the registration forms and allow users to quickly engage in better use of their sites, such as for conversations, commerce or feedback.
- Increased stickiness: Users are more likely to come back since they do not have to remember an additional username-password combination.
- Up-to-date registration information: Due to the need of frequent registrations, users often provide junk or inaccurate personal information. With OpenID, since only a one-time registration is necessary, users are more likely to provide more accurate data.
OpenID thus provides the users with a streamlined and smooth experience and website owners can gain from the huge usability benefit and reduce their clutter.
Why Relying Parties should implement OpenID based authentication?
- Expedited customer acquisition: OpenID allows users to quickly and easily complete the account creation process by eliminating entry of commonly requested fields (email address, gender, birthdates etc.), thus reducing the friction to adopt a new service.
- Outsourcing authentication saves costs: As a relying party you don’t have to worry about lost user names, passwords, a costly infrastructure, upgrading to new standards and devices. You can just focus on your core. From research the average cost per user for professional authentication are approximately €34 per year. In the future, the relying party will end up paying only a few Cents per authentication request (transaction based).
- Reduced user account management costs: The primary cost for most IT organizations is resetting forgotten authentication credentials. By reducing the number of credentials, a user is less likely to forget their credentials. By outsourcing the authentication process to a third-party, the relying party can avoid those costs entirely.
- Your customers are demanding user-centric authentication: User-centric authentication gives your customers comfort. It promises no registration hassle and low barriers of entry to your service. Offering UCA to your customers can be a unique selling point and stimulate user participation.
- Thought leadership: There is an inherent marketing value for an organization to associate itself with activities that promote it as a thought leader. It provides the organization with the means to distinguish itself from its competitors. This is your chance to outpace your competitors.
- Simplified user experience: This is at the end of the list because that is not the business priority. The business priority is the benefit that results from a simplified user experience, not the simplified user experience itself.
- Open up your service to a large group of potential customers: You are probably more interested in the potential customers you don’t know, versus the customers you already service. UCA makes this possible. If you can trust the identity of new customers you can start offering services in a minute.
- The identity provider follows new developments: When a new authentication token or protocol is introduced you don’t have to replace your whole infrastructure.
- Time to market: Due to legislation you are suddenly confronted with an obligation to offer two factor authentications. UCA is very easy to integrate and you are up and running a lot quicker
- Data sharing: If the identity provider also offers the option to provide additional (allowed) attributes of the end-user you don’t have to store all this data yourself. For example, if I go on a holiday for a few weeks, I just update my temporary address instead of calling the customer service of my local newspaper!
- Quickly offer new services under your brand: If you take over a company or want to offer a third party service under your brand/ infrastructure UCA makes it much easier to manage shared users. How much time does this take at the moment?
- Corporate image: As SourceForge states they also offer OpenID support to join the web 2.0 space and benefit from the first mover buzz. Besides adding a good authentication mechanism provided by a trusted identity provider could add value to your own service. It is like adding a trust seal of your SSL certificate provider.
- Extra Traffic: Today you get only those users whom you solicit but miss on those who are solicited by other similar businesses like yours. OpenID brings extra traffic to your website without you spending that extra effort.
- Analytics: Providers can give you much more analytics on your users’ behavior patterns (this can be anonymous to keep user identity private and report something like 30% of people who visit your site also visit site ‘x’).
OpenID and Info-Cards
It is believed that user-id/password based log-in is the oldest, commonly used and easily implementable, but, at the same time, a weak method of authenticating and establishing somebody’s identity.
To overcome this problem and enhance the security aspect of OpenID based login processes, OpenID providers are using new techniques such as Info-cards (virtual cards based on user PC) based authentication. Microsoft is specially working with various leading OpenID providers to make Microsoft CardSpace as the de-facto standard for OpenID authentication.
There are two types of Info-Cards, Self-issued and Managed (or Managed by the provider). Self issued are the ones which are created by user stored on her/his PC and used during the login process. Since these cards are self issued level of verification provided by the users, their use is limited to the self-verified category and as such, provides a more secure replacement for User Id / Password combination only.
On the other hand ‘Managed Cards’ are managed by the specific provider. This can be your OpenID provider or your Bank. In this scenario, the data on the card is validated by the provider significantly enhancing the value of the verification. As such, these cards can easily be used in financial transactions for easing your on-line purchase process or for proving your legal identity.
There is emerging trend to bridge the gap between info-cards (virtual) and smart-cards (physical) and establish the link between them. Data can be copied to and fro giving your virtual card a physical status. In this scenario, your Info card (which was managed by the required management authority like Bank, RTO or so on) can take the place of your identity proof.
Some Interesting Sites Which Accept OpenID
Circavie.Com
An interesting site where you can create your own ‘story of your life’ – an interactive and chronological blog site, but with a difference (and that difference is not about being OpenID enabled) – see it to believe it!
Doxory.Com
If you are the kind of person who simply cannot decide whether to do ‘x’ or ‘y’, then here is the place for you. Put up your question and random strangers from the internet post their advice.
Highrisehq.Com
Here is the perfect solution for all those internet based companies – manage your contacts, to-do lists, e-mail based notifications, and what-not on this site. If the internet is where you work, then this site is perfect for you to get managing your business smoothly!
Foodcandy.Com
If you are a foodie then this site is the place for you! Post your own recipes and access the recipes posted by other people. Read opinions of people who have tried out the different recipes. Hungry?
About SingleID
SingleID is an OpenID provider – the first in India to do so. It allows users to register and create their OpenID(s) for FREE. It provides all the typical OpenID provider functions – allowing users to create their digital identity and using that to login to several OpenID enabled websites across the internet.
OpenID is being hailed as the ‘new face of the internet’ and SingleID is bringing it close to home. The main focus area of the company is to promote usage of OpenID in India.
If a user wants, he can also create multiple SingleID(s) with different account information, to use on different sites. So it allows you – the user – to control your digital identity, much in the same way as a regular login-password would – but with the added benefits of the OpenID technology.
SingleID has created a unique platform for website owners in India to generate a smooth user experience and create a wider base of operations and access for their websites.
Other user-centric services such as Virtual Cards (for more secure authentication) or allowing the use of user specific domain name (e.g. hemant.kulkarni.name) as an OpenID will be offered very soon.
For our partners we provide secured identity storage and authentication and authorization service alleviating headaches of critical security issues related to personal data.
We also provide the OpenID enablement service. Using our services companies can upgrade their user login process by accepting the OpenID based login largely enhancing their user base.
Links for Reference
· SingleID Home Page – http://www.singleid.net and Registration – https://www.singleid.net/register.htm
· OpenID Foundation Website – http://openid.net
· The OpenID Directory – http://openiddirectory.com/
About the author: Hemant Kulkarni is a founder director of SingleID.net. He has more than 25 years of product engineering and consulting experience in domains of networking and communications, Unix Systems and commercial enterprise software. You can reach him at hemant@singleid.net.
 The Indian Express reports that Pune has yet again been chosen as a city to introduce a new hi-tech service:
The Indian Express reports that Pune has yet again been chosen as a city to introduce a new hi-tech service: 


{kind=link}
{kind=link}