Druvaa is a Pune-based startup that sells fast, efficient, and cheap backup (Update: see the comments section for Druvaa’s comments on my use of the word “cheap” here – apparently they sell even in cases where their product is priced above the competing offerings) software for enterprises and SMEs. It makes heavy use of data de-duplication technology to deliver on the promise of speed and low-bandwidth consumption. In this article, reproduced with permission from their blog, they explain what exactly data de-duplication is and how it works.
Definition of Data De-duplication
Data deduplication or Single Instancing essentially refers to the elimination of redundant data. In the deduplication process, duplicate data is deleted, leaving only one copy (single instance) of the data to be stored. However, indexing of all data is still retained should that data ever be required.
Example
A typical email system might contain 100 instances of the same 1 MB file attachment. If the email platform is backed up or archived, all 100 instances are saved, requiring 100 MB storage space. With data deduplication, only one instance of the attachment is actually stored; each subsequent instance is just referenced back to the one saved copy reducing storage and bandwidth demand to only 1 MB.
Technological Classification
The practical benefits of this technology depend upon various factors like –
Point of Application – Source Vs Target
Time of Application – Inline vs Post-Process
Granularity – File vs Sub-File level
Algorithm – Fixed size blocks Vs Variable length data segments
A simple relation between these factors can be explained using the diagram below –
Target Vs Source based Deduplication
Target based deduplication acts on the target data storage media. In this case the client is unmodified and not aware of any deduplication. The deduplication engine can embedded in the hardware array, which can be used as NAS/SAN device with deduplication capabilities. Alternatively it can also be offered as an independent software or hardware appliance which acts as intermediary between backup server and storage arrays. In both cases it improves only the storage utilization.
On the contrary Source based deduplication acts on the data at the source before it’s moved. A deduplication aware backup agent is installed on the client which backs up only unique data. The result is improved bandwidth and storage utilization. But, this imposes additional computational load on the backup client.
Inline Vs Post-process Deduplication
In target based deduplication, the deduplication engine can either process data for duplicates in real time (i.e. as and when its send to target) or after its been stored in the target storage.
The former is called inline deduplication. The obvious advantages are –
Increase in overall efficiency as data is only passed and processed once
The processed data is instantaneously available for post storage processes like recovery and replication reducing the RPO and RTO window.
the disadvantages are –
Decrease in write throughput
Extent of deduplication is less – Only fixed-length block deduplication approach can be use
The inline deduplication only processed incoming raw blocks and does not have any knowledge of the files or file-structure. This forces it to use the fixed-length block approach (discussed in details later).
The post-process deduplication asynchronously acts on the stored data. And has an exact opposite effect on advantages and disadvantages of the inline deduplication listed above.
File vs Sub-file Level Deduplication
The duplicate removal algorithm can be applied on full file or sub-file levels. Full file level duplicates can be easily eliminated by calculating single checksum of the complete file data and comparing it against existing checksums of already backed up files. It’s simple and fast, but the extent of deduplication is very less, as it does not address the problem of duplicate content found inside different files or data-sets (e.g. emails).
The sub-file level deduplication technique breaks the file into smaller fixed or variable size blocks, and then uses standard hash based algorithm to find similar blocks.
Fixed-Length Blocks v/s Variable-Length Data Segments
Fixed-length block approach, as the name suggests, divides the files into fixed size length blocks and uses simple checksum (MD5/SHA etc.) based approach to find duplicates. Although it’s possible to look for repeated blocks, the approach provides very limited effectiveness. The reason is that the primary opportunity for data reduction is in finding duplicate blocks in two transmitted datasets that are made up mostly – but not completely – of the same data segments.
For example, similar data blocks may be present at different offsets in two different datasets. In other words the block boundary of similar data may be different. This is very common when some bytes are inserted in a file, and when the changed file processes again and divides into fixed-length blocks, all blocks appear to have changed.
Therefore, two datasets with a small amount of difference are likely to have very few identical fixed length blocks.
Variable-Length Data Segment technology divides the data stream into variable length data segments using a methodology that can find the same block boundaries in different locations and contexts. This allows the boundaries to “float” within the data stream so that changes in one part of the dataset have little or no impact on the boundaries in other locations of the dataset.
ROI Benefits
Each organization has a capacity to generate data. The extent of savings depends upon – but not directly proportional to – the number of applications or end users generating data. Overall the deduplication savings depend upon following parameters –
No. of applications or end users generating data
Total data
Daily change in data
Type of data (emails/ documents/ media etc.)
Backup policy (weekly-full – daily-incremental or daily-full)
Retention period (90 days, 1 year etc.)
Deduplication technology in place
The actual benefits of deduplication are realized once the same dataset is processed multiple times over a span of time for weekly/daily backups. This is especially true for variable length data segment technology which has a much better capability for dealing with arbitrary byte insertions.
Numbers
While some vendors claim 1:300 ratios of bandwidth/storage saving. Our customer statistics show that, the results are between 1:4 to 1:50 for source based deduplication.
And this is not confined to national boundaries. It is one of only two (as far as I know) Pune-based companies to be featured in TechCrunch (actually TechCrunchIT), one of the most influential tech blogs in the world (the other Pune company featured in TechCrunch is Pubmatic).
Why all this attention for Druvaa? Other than the fact that it has a very strong team that is executing quite well, I think two things stand out:
It is one of the few Indian product startups that are targeting the enterprise market. This is a very difficult market to break into, both, because of the risk averse nature of the customers, and the very long sales cycles.
Unlike many other startups (especially consumer oriented web-2.0 startups), Druvaa’s products require some seriously difficult technology.
The rest of this article talks about their technology.
Druvaa has two main products. Druvaa inSync allows enterprise desktop and laptop PCs to be backed up to a central server with over 90% savings in bandwidth and disk storage utilization. Druvaa Replicator allows replication of data from a production server to a secondary server near-synchronously and non-disruptively.
We now dig deeper into each of these products to give you a feel for the complex technology that goes into them. If you are not really interested in the technology, skip to the end of the article and come back tomorrow when we’ll be back to talking about google keyword searches and web-2.0 and other such things.
Druvaa Replicator
Overall schematic set-up for Druvaa Replicator
This is Druvaa’s first product, and is a good example of how something that seems simple to you and me can become insanely complicated when the customer is an enterprise. The problem seems rather simple: imagine an enterprise server that needs to be on, serving customer requests, all the time. If this server crashes for some reason, there needs to be a standby server that can immediately take over. This is the easy part. The problem is that the standby server needs to have a copy of the all the latest data, so that no data is lost (or at least very little data is lost). To do this, the replication software continuously copies all the latest updates of the data from the disks on the primary server side to the disks on the standby server side.
This is much harder than it seems. A simple implementation would simply ensure that every write of data that is done on the primary is also done on the standby storage at the same time (synchronously). This is unacceptable because each write would take unacceptably long and this would slow down the primary server too much.
If you are not doing synchronous updates, you need to start worrying about write order fidelity.
Write-order fidelity and file-system consistency
If a database writes a number of pages to the disk on your primary server, and if you have software that is replicating all these writes to a disk on a stand-by server, it is very important that the writes should be done on the stand-by in the same order in which they were done at the primary servers. This section explains why this is important, and also why doing this is difficult. If you know about this stuff already (database and file-system guys) or if you just don’t care about the technical details, skip to the next section.
Imagine a bank database. Account balances are stored as records in the database, which are ultimately stored on the disk. Imagine that I transfer Rs. 50,000 from Basant’s account to Navin’s account. Suppose Basant’s account had Rs. 3,00,000 before the transaction and Navin’s account had Rs. 1,00,000. So, during this transaction, the database software will end up doing two different writes to the disk:
write #1: Update Basant’s bank balance to 2,50,000
write #2: Update Navin’s bank balance to 1,50,000
Let us assume that Basant and Navin’s bank balances are stored on different locations on the disk (i.e. on different pages). This means that the above will be two different writes. If there is a power failure, after write #1, but before write #2, then the bank will have reduced Basant’s balance without increasing Navin’s balance. This is unacceptable. When the database server restarts when power is restored, it will have lost Rs. 50,000.
After write #1, the database (and the file-system) is said to be in an inconsistent state. After write #2, consistency is restored.
It is always possible that at the time of a power failure, a database might be inconsistent. This cannot be prevented, but it can be cured. For this, databases typically do something called write-ahead-logging. In this, the database first writes a “log entry” indicating what updates it is going to do as part of the current transaction. And only after the log entry is written does it do the actual updates. Now the sequence of updates is this:
write #0: Write this log entry “Update Basant’s balance to Rs. 2,50,000; update Navin’s balance to Rs. 1,50,000” to the logging section of the disk
write #1: Update Basant’s bank balance to 2,50,000
write #2: Update Navin’s bank balance to 1,50,000
Now if the power failure occurs between writes #0 and #1 or between #1 and #2, then the database has enough information to fix things later. When it restarts, before the database becomes active, it first reads the logging section of the disk and goes and checks whether all the updates that where claimed in the logs have actually happened. In this case, after reading the log entry, it needs to check whether Basant’s balance is actually 2,50,000 and Navin’s balance is actually 1,50,000. If they are not, the database is inconsisstent, but it has enough information to restore consistency. The recovery procedure consists of simply going ahead and making those updates. After these updates, the database can continue with regular operations.
(Note: This is a huge simplification of what really happens, and has some inaccuracies – the intention here is to give you a feel for what is going on, not a course lecture on database theory. Database people, please don’t write to me about the errors in the above – I already know; I have a Ph.D. in this area.)
Note that in the above scheme the order in which writes happen is very important. Specifically, write #0 must happen before #1 and #2. If for some reason write #1 happens before write #0 we can lose money again. Just imagine a power failure after write #1 but before write #0. On the other hand, it doesn’t really matter whether write #1 happens before write #2 or the other way around. The mathematically inclined will notice that this is a partial order.
Now if there is replication software that is replicating all the writes from the primary to the secondary, it needs to ensure that the writes happen in the same order. Otherwise the database on the stand-by server will be inconsistent, and can result in problems if suddenly the stand-by needs to take over as the main database. (Strictly speaking, we just need to ensure that the partial order is respected. So we can do the writes in this order: #0, #2, #1 and things will be fine. But #2, #0, #1 could lead to an inconsistent database.)
Replication software that ensures this is said to maintain write order fidelity. A large enterprise that runs mission critical databases (and other similar software) will not accept any replication software that does not maintain write order fidelity.
Why is write-order fidelity difficult?
I can here you muttering, “Ok, fine! Do the writes in the same order. Got it. What’s the big deal?” Turns out that maintaining write-order fidelity is easier said than done. Imagine the your database server has multiple CPUs. The different writes are being done by different CPUs. And the different CPUs have different clocks, so that the timestamps used by them are not nessarily in sync. Multiple CPUs is now the default in server class machines. Further imagine that the “logging section” of the database is actually stored on a different disk. For reasons beyond the scope of this article, this is the recommended practice. So, the situation is that different CPUs are writing to different disks, and the poor replication software has to figure out what order this was done in. It gets even worse when you realize that the disks are not simple disks, but complex disk arrays that have a whole lot of intelligence of their own (and hence might not write in the order you specified), and that there is a volume manager layer on the disk (which can be doing striping and RAID and other fancy tricks) and a file-system layer on top of the volume manager layer that is doing buffering of the writes, and you begin to get an idea of why this is not easy.
Naive solutions to this problem, like using locks to serialize the writes, result in unacceptable degradation of performance.
Druvaa Replicator has patent-pending technology in this area, where they are able to automatically figure out the partial order of the writes made at the primary, without significantly increasing the overheads. In this article, I’ve just focused on one aspect of Druvaa Replicator, just to give an idea of why this is so difficult to build. To get a more complete picture of the technology in it, see this white paper.
Druvaa inSync
Druvaa inSync is a solution that allows desktops/laptops in an enterprise to be backed up to a central server. (The central server is also in the enterprise; imagine the central server being in the head office, and the desktops/laptops spread out over a number of satellite offices across the country.) The key features of inSync are:
The amount of data being sent from the laptop to the backup server is greatly reduced (often by over 90%) compared to standard backup solutions. This results in much faster backups and lower consumption of expensive WAN bandwidth.
It stores all copies of the data, and hence allows timeline based recovery. You can recover any version of any document as it existed at any point of time in the past. Imagine you plugged in your friend’s USB drive at 2:30pm, and that resulted in a virus that totally screwed up your system. Simply uses inSync to restore your system to the state that existed at 2:29pm and you are done. This is possible because Druvaa backs up your data continuously and automatically. This is far better than having to restore from last night’s backup and losing all data from this morning.
It intelligently senses the kind of network connection that exists between the laptop and the backup server, and will correspondingly throttle its own usage of the network (possibly based on customer policies) to ensure that it does not interfere with the customer’s YouTube video browsing habits.
Data de-duplication
Overview of Druvaa inSync. 1. Fingerprints computed on laptop sent to backup server. 2. Backup server responds with information about which parts are non-duplicate. 3. Non-duplicate parts compressed, encrypted and sent.
Let’s dig a little deeper into the claim of 90% reduction of data transfer. The basic technology behind this is called data de-duplication. Imagine an enterprise with 10 employees. All their laptops have been backed up to a single central server. At this point, data de-duplication software can realize that there is a lot of data that has been duplicated across the different backups. i.e. the 10 different backups of contain a lot of files that are common. Most of the files in the C:\WINDOWS directory. All those large powerpoint documents that got mail-forwarded around the office. In such cases, the de-duplication software can save diskspace by keeping just one copy of the file and deleting all the other copies. In place of the deleted copies, it can store a shortcut indicating that if this user tries to restore this file, it should be fetched from the other backup and then restored.
Data de-duplication doesn’t have to be at the level of whole files. Imagine a long and complex document you created and sent to your boss. Your boss simply changed the first three lines and saved it into a document with a different name. These files have different names, and different contents, but most of the data (other than the first few lines) is the same. De-duplication software can detect such copies of the data too, and are smart enough to store only one copy of this document in the first backup, and just the differences in the second backup.
The way to detect duplicates is through a mechanism called document fingerprinting. Each document is broken up into smaller chunks. (How do determine what constitutes one chunk is an advanced topic beyond the scope of this article.) Now, a short “fingerprint” is created for each chunk. A fingerprint is a short string (e.g. 16 bytes) that is uniquely determined by the contents of the entire chunk. The computation of a fingerprint is done in such a way that if even a single byte of the chunk is changed, the fingerprint changes. (It’s something like a checksum, but a little more complicated to ensure that two different chunks cannot accidently have the same checksum.)
All the fingerprints of all the chunks are then stored in a database. Now everytime a new document is encountered, it is broken up into chunks, fingerprints computed and these fingerprints are looked up in the database of fingerprints. If a fingerprint is found in the database, then we know that this particular chunk already exists somewhere in one of the backups, and the database will tell us the location of the chunk. Now this chunk in the new file can be replaced by a shortcut to the old chunk. Rinse. Repeat. And we get 90% savings of disk space. The interested reader is encouraged to google Rabin fingerprinting, shingling, Rsync for hours of fascinating algorithms in this area. Before you know it, you’ll be trying to figure out how to use these techniques to find who is plagiarising your blog content on the internet.
Back to Druvaa inSync. inSync does fingerprinting at the laptop itself, before the data is sent to the central server. So, it is able to detect duplicate content before it gets sent over the slow and expensive net connection and consumes time and bandwidth. This is in contrast to most other systems that do de-duplication as a post-processing step at the server. At a Fortune 500 customer site, inSync was able reduce the backup time from 30 minutes to 4 minutes, and the disk space required on the server went down from 7TB to 680GB. (source.)
Again, this was just one example used to give an idea of the complexities involved in building inSync. For more information on other distinguishinging features, check out the inSync product overview page.
Have questions about the technology, or about Druvaa in general? Ask them in the comments section below (or email me). I’m sure Milind/Jaspreet will be happy to answer them.
Also, this long, tech-heavy article was an experiment. Did you like it? Was it too long? Too technical? Do you want more articles like this, or less? Please let me know.
This article discussing strategies for achieving high availability of applications based on cloud computing services is reprinted with permission from the blog of Mukul Kumar of Pune-based ad optimization startup PubMatic
The high availability of these cloud services becomes more important with some of these companies relying on these services for their critical infrastructure. Recent outages of Amazon S3 (here and here) have raised some important questions such as this – S3 Outage Highlights Fragility of Web Services and this. [A simple search on search.twitter.com can tell you things that you won’t find on web pages. Check it out with this search, this and this.]
Here I am writing of some thoughts on how these cloud services can be made highly available, by following the traditional path of redundancy.
The traditional way of using AWS S3 is to use it with AWS EC2 (config #0). Configurations such as on the left can be made to make your computing and storage not dependent on the same service provider. Config #1, config #2 and config #3 mix and match some of the more flexible computing services with storage services. In theory the compute and the storage can be separately replaced by a colo service.
The configurations on the right are examples of providing high availability by making a “hot-standby”. Config #4 makes the storage service hot-standby and config #5 separates the web-service layer from the application layer, and makes the whole application+storage layer as hot-standby.
A hot-standby requires three things to be configured – rsync, monitoring and switchover. rsync needs to be configured between hot-standby servers, to make sure that most of the application and data components are up to date on the online-server. So for example in config #4 one has to rsync ‘Amazon S3’ to ‘Nirvanix’ – that’s pretty easy to setup. In fact, if we add more automation, we can “turn-off” a standby server after making sure that the data-source is synced up. Though that assumes that the server provisioning time is an acceptable downtime, i.e. the RTO (Recovery time objective) is within acceptable limits.
This also requires that you are monitoring each of the web services. One might have to do service-heartbeating – this has to be designed for the application, this has to be designed differently for monitoring Tomcat, MySQL, Apache or their sub-components. In theory it would be nice if a cloud computing service would export APIs, for example an API for http://status.aws.amazon.com/ , http://status.mosso.com/ or http://heartbeat.skype.com/. However, most of the times the status page is updated much later after the service goes down. So, that wouldn’t help much.
Switchover from the online-server/service to the hot-standby would probably have to be done by hand. This requires a handshake with the upper layer so that requests stop and start going to the new service when you trigger the switchover. This might become interesting with stateful-services and also where you cannot drop any packets, so quiscing may have to be done for the requests before the switchover takes place.
Above are two configurations of multi-tiered web-services, where each service is built on a different cloud service. This is a theoretical configuration, since I don’t know of many good cloud services, there are only a few. But this may represent a possible future, where the space becomes fragmented, with many service providers.
Config #7 is config #6 with hot-standby for each of the service layers. Again this is a theoretical configuration.
Cost Impact
Any of the hot-standby configurations would have cost impact – adding any extra layer of high-availability immediately adds to the cost, at least doubling the cost of the infrastructure. This cost increase can be reduced by making only those parts of your infrastructure highly-available that affect your business the most. It depends on how much business impact does a downtime cause, and therefore how much money can be spent on the infrastructure.
One of the ways to make the configurations more cost effective is to make them active-activeconfiguration also called aload balancedconfiguration – these configurations would make use of all the allocated resources and would send traffic to both the servers. This configuration is much more difficult to design – for example if you put the hot-standby-storage in active-active configuration then every “write” (DB insert) must go to both the storage-servers, writes (DB insert) must not complete on any replicas (also called mirrored write consistency).
Cloud Computing becoming mainstream
As cloud computing becomes more mainstream – larger web companies may start using these services, they may put a part of their infrastructure on a compute cloud. For example, I can imagine a cloud dedicated for “data mining” being used by several companies, these may have servers with large HDDs and memory and may specialize in cluster software such as Hadoop.
Lastly I would like to cover my favorite topic –why would I still use services that cost more for my core services instead of using cloud computing?
The most important reason would be 24×7 support. Hosting providers such as servepath and rackspace provide support. When I give a call to the support at 2PM India time, they have a support guy picking up my calls – that’s a great thing. Believe me 24×7 support is a very difficult thing to do.
These hosting providers give me more configurability for RAM/disk/CPU
I can have more control over the network and storage topology of my infrastructure
Point #2 above can give me consistent throughput and latency for I/O access, and network access
These services give me better SLAs
Security
About the Author
Mukul Kumar, is a founding engineer and VP of Engineering at Pubmatic. He is based in Pune and responsible for PubMatic’s engineering team. Mukul was previously the Director of Engineering at PANTA Systems, a high performance computing startup. Previous to that he joined Veritas India as the 13th employee and was Director of Engineering for the NetBackup group, one of Veritas’ main products. He has filed for 14 patents in systems software, storage software, and application software and proudly proclaims his love of π and can recite it to 60 digits. Mukul is a graduate of IIT Kharagpur with a degree in electrical engineering.
(by Bob Spurzem, Director of International Business, Mimosa Systems, and T.M. Ravi, Founder, President and CEO, Mimosa Systems. This article is reposted with permission from CSI Pune‘s newsletter, DeskTalk. The full newsletter is available here.)
In this era of worldwide electronic communication and fantastic new business applications, the amount of unstructured, electronic information generated by enterprises is exploding. This growth of unstructured information is the driving force of a significant surge in knowledge worker productivity and is creating an enormous risk for enterprises with no tools to manage it. Content Archiving is a new class of enterprise application designed for managing user-generated, unstructured electronic information. The purpose of Content Archiving is to manage unstructured information over the entire lifecycle, ensuring preservation of valuable electronic information, while providing easy access to historical information by knowledge workers. With finger-tip access to years of historical business records, workers make informed decisions driving top line revenue. Workers with legal and compliance responsibility search historical records easily in response to regulatory and litigation requests; thereby reducing legal costs and compliance risk. Using Content Archiving enterprises gain “finger-tip” access to important historical information – an important competitive advantage helping them be successful market leaders.
Unstructured Electronic Information
One of the most remarkable results of the computer era is the explosion of usergenerated electronic digital information. Using a plethora of software applications, including the widely popular Microsoft® Office® products, users generate millions of unmanaged data files. To share information with co-workers and anyone else, users attach files to email and instantly files are duplicated to unlimited numbers of users worldwide. The University of California, Berkeley School of Information Management and Systems measured the impact of electronically stored information and the results were staggering. Between the years 1992 to 2003, they estimated that total electronic information grew about 30% per year. Per user per year, this corresponds to almost 800 MB of electronic information. And the United States accounts for only 40% of the world’s new electronic information.
Email generates about 4,000,000 terabytes of new information each year — worldwide.
Instant messaging generates five billion messages a day (750GB), or about 274 terabytes a year.
The World Wide Web contains about 170 terabytes of information on its surface; in volume this is seventeen times the size of the Library of Congress print collections.
This enormous growth in electronic digital information has created many unforeseen benefits. Hal R. Varian, a business professor at the University of California, Berkeley, notes that, “From 1974 to 1995, productivity in the United States grew at around 1.4 percent a year. Productivity growth accelerated to about 2.5 percent a year from 1995 to 2000. Since then, productivity has grown at a bit over 3 percent a year, with the last few years looking particularly strong. But unlike the United States, European countries have not seen the same surge in productivity growth in the last ten years. The reason for this is that United States companies are much farther up the learning curve than European companies for applying the benefits of information technology.”
Many software applications are responsible for the emergence of the electronic office place and this surge in productivity growth, but none more so than email. From its humble beginning as a simple messaging application for users of ARPANET in the early 1970’s, email has grown to become the number one enterprise application. In 2006, over 171 billion emails were being sent daily worldwide, a 26% increase over 2005 and this figure is forecasted to continue to grow 25-30% throughout the remaining decade. A new survey by Osterman Research polled 394 email users, “How important is your email system in helping you get your work done on a daily basis?” 76% reported that it is “extremely important”. The Osterman survey revealed that email users spend on average 2 hours 15 minutes each day doing something in email, but 28% users spend more than 3 hours per day using email. As confirmed by this survey and many others, email has become the most important tool for business communication and contributes significantly to user productivity.
The explosive growth in electronically stored information has created many challenges and has created a fundamental change in the way electronic digital information is accessed. Traditionally, electronic information was managed in closely guarded applications used by manufacturing, accounting and engineering and only accessed by a small number of trained professionals. These forms of electronic information are commonly referred to as structured electronic information. User-generated electronic information is quite different because it is in the hands of all workers – trained and untrained. User-generated information is commonly referred to as unstructured electronic information. Where many years of IT experience have solved the problems of managing structured information; the tools and methods necessary to manage unstructured information, for the most part, do not exist. For a typical enterprise, as much as 50% of total storage capacity is consumed by unstructured data and another 15-20% is made up of email data. The remaining 25-30% of enterprise storage is made up of structured data in enterprise databases.
Content Archiving
User-generated, unstructured electronic information is creating a chasm between IT staff whose responsibility it is to manage electronic information and knowledge workers who want to freely access current and historical electronic information. Knowledge workers desire “finger-tip” access to years of information which strains the ability of IT to provide information protection and availability, cost effectively. Compliance officers desire tools to search electronic information and preserve information for regulatory audits. And overshadowing everything is the need for information security. User-generated electronic information is often highly sensitive and requires secure access. As opposed to information that exists on the World Wide Web, electronic information that exists in organizations is meant only for authorized access.
Content Archiving represents a new class of enterprise application designed for managing user-generated unstructured electronic information in a way that addresses the needs of IT, knowledge workers and compliance officers. The nature of Content Archiving is to engage seamlessly with the applications that generate unstructured electronic information in a continuous manner for information capture, and to provide real-time end-user access for fast search and discovery. The interfaces currently used to access unstructured information (e.g. Microsoft Outlook®) are the same interfaces used by Content Archiving to provide end users with secure “finger-tip” access to volumes of electronic information.
Content Archiving handles a large variety of user-generated electronic information. Email is the dominate form of usergenerated electronic information and is included in this definition. So too are Microsoft Office files (e.g. Word, Excel, PowerPoint, etc.) and the countless other file formats such as .PDF and .HTML. Files that are commonly sent via email as attachments are included in both the context of email and as standalone files. In addition to email and files, there are a large number of information types that are not text based, and include digital telephony, digital pictures and digital movies. The growing popularity of digital pictures (.JPG), audio and voice mail files (.WAV, .WMA) and video files is paving the way for a new generation of communication applications. It is within reason that in the near future full length video recordings will be shared just as easily as Excel spreadsheets are today. All these user-generated data types fall under the definition of Content.
Content Archiving distinguishes itself from traditional data protection applications. Data protection solves the important problem of restoring electronic information, but does little more. Archiving, on the other hand, is a business intelligence application that solves problems such as providing secure access to electronic information for quick search and legal discovery; measuring how much information exists; identifying what type of data exists; locating where data exists and determining when data was last accessed. For managing unstructured electronic information, Content Archiving delivers important benefits for business intelligence and goes far beyond the simple recovery function that data protection provides. Using tools that archiving provides, knowledge users can easily search years of historical information and benefit from the business information contained within.
Information Life-Cycle Management
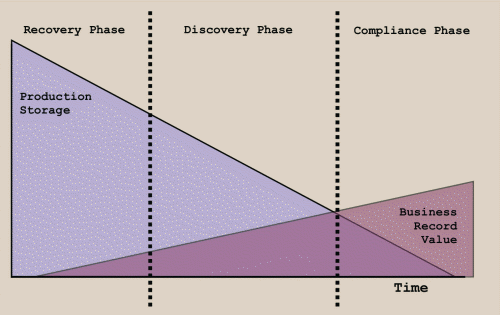
Content Archiving recognizes that electronic information must be managed over its entire life-cycle. Information that was recently created has different needs and requirements than the same information years later and should be managed accordingly. Three distinct phases exist for the management of electronic information, which are the recovery phase, discovery phase and compliance phase (see figure). It is the strategic purpose of Content Archiving to manage electronic information throughout the entire life-cycle; recognizing the value of information in the short-term for production and long-term as a record of business; while continually driving information storage levels down to reduce storage costs and preserving access to information.
During the recovery phase all production information requires equal protection and must be available for fast recovery should a logical error occur, or a hardware failure strikes the production servers. Continuous capture of information reduces the risk of losing information and supports fast disk-based recovery. The same information stores can be accessed by end users who desire easy access to restore deleted files. Content Archiving supports the recovery phase by performing as a disk-based continuous data protection application. As compared to tape-based recovery, Content Archiving can restore information more quickly and with less loss of information. It captures all information in real-time and it keeps all electronic information on cost-efficient storage where it is available for fast recovery and also can be easily accessed by end users and auditors for compliance and legal discovery. The length of the recovery phase varies according to individual needs, but is typically 6-12 months.
At a point in time, which varies by organization, the increasing volume of current and historical information puts an unmanageable strain on production servers. At the same time the value of the historical electronic information decreases because it is no longer required for recovery. This is called the discovery phase. The challenge in the discovery phase is to reduce the volume of historical information while continuing to provide easy access to all information for audits and legal discovery. Content Archiving provides automated retention and disposition policies that are intelligent and can distinguish between current information and information that has been deleted by end users. Retention rules automatically dispose of information according to policies defined by the administrator. Further reduction is achieved by removing duplicates. For audits and legal discovery, Content Archiving keeps information in a secure, indexed archive and provides powerful search tools that allow auditors quick access to all current and historical information. By avoiding using backup tapes, searches of historical information can be performed quickly and reliably; thereby reducing legal discovery costs.
Following the discovery phase, electronic information must be managed and preserved according to industry rules for records retention. This phase is called the compliance phase. Depending on the content, information may be required to be archived indefinitely. Storing information long-term is a technical challenge and costly if not done correctly. Content Archiving addresses the challenges of the compliance phase in two ways. First, Content Archiving provides tools which allow in-house experts, who know best what information is a record of business, to preserve information. Discovery tools enable auditors and legal counsel to flag electronic information as a business record or disposable. Second, Content Archiving manages electronic information in dedicated file containers. File containers are designed for long-term retention on tiered storage (e.g. tape, optical) for economic reasons and have self-contained indexes for reliable long-term access of information.
Conclusion
The explosive growth in user-generated electronic information has been a powerful benefit to knowledge worker productivity but has created many challenges to enterprises. IT staff is challenged to manage the rapidly growing information stores while keeping applications running smoothly. Compliance and legal staff are challenged to respond to regulatory audits and litigation requests to search and access electronic information quickly. Content Archiving is a new class of enterprise application designed to manage unstructured electronic information over its entire life-cycle. Adhering to architectural design rules that ensure no interruption to the source application, secure access and scalability, Content Archiving manages information upon creation during the recovery phase, the discovery phase and the compliance phase where information is preserved as a long-term business record. Content Archiving provides IT staff, end users as well compliance and legal staff with the business intelligence tools they require to manage unstructured information economically while meeting demands for quick, secure access and legal and regulatory preservation.
About the Authors
Bob Spurzem
Director International Business
Mimosa Systems
Bob has 20+ years experience in high technology product development and marketing and currently he is a Director International Business with Mimosa Systems Inc. With significant experience throughout the product life cycle, from market requirements and competitive research, through positioning, sales collateral development and product launch, he has a strong focus in bringing new products to market. Prior to this his experience includes work as a Senior Product Marketing Manager for Legato Systems and Veritas Software companies. Robert has an MBA from Santa Clara University and a Masters Degree in Biomedical Engineering from Northwestern University
T. M. Ravi
Co-founder, President, and CEO
Mimosa Systems
T. M. Ravi has had a long career with broad experience in enterprise management and storage. Before Mimosa Systems, Ravi was founder and CEO of Peakstone Corporation, a venture-financed startup providing performance management solutions for Fortune 500 companies. Previously, Ravi was vice president of marketing at Computer Associates (CA). At Computer Associates, Ravi was responsible for the core line of CA enterprise management products, including CA Unicenter, as well as the areas of application, systems and network management; software distribution; and help desk, security, and storage management. He joined CA through the $1.2 billion acquisition of Cheyenne Software, the market leader in storage management and antivirus solutions. At Cheyenne Software, Ravi was the vice president responsible for managing the company’s successful Windows NT business with products such as ARCserve backup and InocuLAN antivirus. Prior to Cheyenne, Ravi founded and was CEO of Media Blitz, a provider of Windows NT storage solutions that was acquired by Cheyenne Software. Earlier in his career, Ravi worked in Hewlett-Packard’s Information Architecture Group, where he did product planning for client/server and storage solutions.
T.M. Ravi, CEO of Mimosa, gave talk on what he sees as challenges in storage/ILM. New requirements coming from the customers – Huge amounts of user-generated unstructured data in enterprises. Must manage it properly for legal, security and business reasons. Interesting new trends coming from the technology side – new/cheap disks. De-duplication. Storage intensive apps (eg. video). Flash storage. Green storage (i.e. energy conscious storage). SaaS and storage in the cloud (e.g. Amazon S3). Based on this, storage software should focus on these things: 1. Increase Information content of data 2. Improve security. 3. Reduce legal risk. Now he segues into a pitch for Mimosa’s products. i.e. You must have an enterprise-wide archive: 1. continuous capture (i.e. store all versions of the data). 2. Full text indexing of all the content and allow users to search by keyword. 3. Single instance storage (SIS) aka De-duplication, to reduce the storage requirements. 4. Retention policies. Mimosa is an archiving appliance that can be used for 1. ediscovery, 2. recovery, 3. end-user searches, 4. storage cost reduction.
Then there was a presentation from IBM on General Parallel File System (GPFS). Parallel, highly available distributed file system. I did not really understand how this is significantly different from all the other such products already out there. Also, I am not sure what part of this work is being done in Pune. Caching of files over WAN in GPFS (to improve performance when it is being accessed from a remote location) is being developed here (Ujjwal Lanjewar).
There was also a presentation on the SAN simulator tool. This is something that allows you to simulate a storage area network, including switches and disk arrays. It has been open-sourced and can be downloaded here. A lot of the work for this tool happens in Pune (Pallavi Galgali).
Bernali from Coriolis demonstrated CoLaMa – a virtual machine lifecycle manager a virtual machine lifecycle manager. This is essentially CVS for virtual machine images. A version management software to keep track of all your VM images. Check out image. Work on it. Check it in. A new version gets stored in the repository. And it only stores the differences between the image – so space savings. It auto-extracts info like OS info, patchlevel etc.
Coriolis’ was the only live demo. The others were flash demos which looked lame (and had audio problems). Suggestion to all – if you are going to give a flash demo, at least turn off the audio and do the talking yourself. This would involve the audience much better.
Abhinav Jawadekar gave nice introductory talk on the various interesting technologies and trends in storage. It would have been very useful and helpful for someone new to the field. However, in this case, I think it was wasted on audience most of who’ve been doing this for 5+ years. The only new stuff was in the last few slides that were about energy aware storage (aka green storage). (For example, he pointed out that data-center class storage in Pune is very expensive due to the high storage costs – due to power, cooling, UPS, genset, the operating costs of a 42U rack are $800 to $900 per month.)
The panel discussion touched upon a number of topics, not all of them interesting. I did not really capture notes of that.
Overall, it was an interesting evening. With about 50 people attending, the turnout was a little lower than I expected. I’m not sure what needs to be done in Pune to get people to attend. If you have suggestions, let me know. If you are interested in getting in touch with any of the people mentioned above, let me know, and I can connect you.
What: Seminar on Information Lifecycle Management. ILM consists all the technologies required during the lifetime of some data stored in an enterprise. How data comes in, where it is stored, the storage hardware/software and architecture, how it is archived and backed up, retention policies, and deletion policies.
When: Thursday, 29 May 2008, 4pm to 9pm
Where: National Insurance Academy 25,Balewadi, Baner Road
6:45 pm – 7:30 pm
Technical talk – Most promising new technologies in Storage and ILM space by by Abhinav Jawadekar – Founder, Sound Paradigm, Software Engineering Services.
7:30 pm – 8:15 pm
Panel discussion – Technology Trends in Storage and its correlation with Career Opportunities . Panelists are Surya Narayanan (Symphony), K K George (Zmanda Technologies), Monish Darda (Bladelogic), Bhushan Pandit (Nes technologies), V. Ganesh (Symantec). Moderated by Hemant Joshi (nFactorial Software)
8:15 pm onwards: Dinner
The event is open to everybody, but you have to register online. Fees are Rs. 400 for members, Rs. 500 for non-members.
Recovery Point Objective (RPO) and Recovey Time Objective (RTO) are some of the most important parameters of a disaster recovery or data protection plan. These objectives guide the enterprises in choosing an optimal data backup (or rather restore) plan.
“Recovery Point Objective (RPO) describes the amount of data lost – measured in time. Example: After an outage, if the last available good copy of data was from 18 hours ago, then the RPO would be 18 hours.”
In other words it is the answer to the question – “Up to what point in time can the data be recovered ?“.
“The Recovery Time Objective (RTO) is the duration of time and a service level within which a business process must be restored after a disaster in order to avoid unacceptable consequences associated with a break in continuity.
[…]
It should be noted that the RTO attaches to the business process and not the resources required to support the process.”
In another words it is the answer to the question – “How much time did you take to recover after notification of a business process disruption ?“
The RTO/RPO and the results of the Business Impact Analysis (BIA) in its entirety provide the basis for identifying and analyzing viable strategies for inclusion in the business continuity plan. Viable strategy options would include any which would enable resumption of a business process in a time frame at or near the RTO/RPO. This would include alternate or manual workaround procedures and would not necessarily require computer systems to meet the objectives.
There is always a gap between the actuals (RTA/RPA) and objectives introduced by various manual and automated steps to bring the business application up. These actuals can only be exposed by disaster and business disruption rehearsals.
Some Examples –
Traditional Backups
In traditional tape backups, if your backup plan takes 2 hours for a scheduled backup at 0600 hours and 1800 hours, then a primary site failure at 1400 hrs would leave you with an option of restoring from the 0600 hrs backup which means RPA of 8 hours and 2 hours RTA.
Continuous Replication
Replication provides higher RPO guarantees as the target system contains a mirrored image of the source. The RPA values depend upon how fast the changes are applied and if the replication is synchronous or asynchronous. RPO is dependent only on how soon the data on target/replicated site can be made available to the application.
About Druvaa Replicator
Druvaa Replicator is a Continuous Data Protection and Replication (CDP-R) product which near-synchronously and non-disruptively replicates changes on production sever to target site and provides point-in-time snapshots for instant data access.
The partial synchronous replication ensures that the data is written to a local or remote cache (caching server) before its application can write locally. This ensures up to 5 sec RPO guarantees . CDP technology (still beta) enables up to 1024 snapshots (beta) at that target storage which helps the admin to access current or any past point-in-time consistent image of data instantly, ensuring under 2 sec RTO.




![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=36a76173-9f53-4f2e-9dc1-53de4f7866bf)



![[Image: Basic cloud computing architectures config #1 to #3]](http://farm4.static.flickr.com/3191/2706605751_1da653b46a_o.png)
![[Image: Cloud computing HA configuraion #4]](http://farm4.static.flickr.com/3221/2706606111_48a075ce8f_o.png)
![[Image: Cloud computing Hot Standby Config #5]](http://farm4.static.flickr.com/3164/2707423692_f80478a7cc_o.png)
![[Image: Cloud computing multi-tier config #6]](http://farm4.static.flickr.com/3015/2707423842_ee81cf527e_o.png)
![[Image: Multi-tier cloud computing with HA]](http://farm4.static.flickr.com/3048/2706605363_0ae1236762_o.png)