This weekend, at Barcamp Pune 5, I gave a presentation targeted towards people who are new to Twitter, or who do not see what the hype is all about. The presentation went into the reasons why people find Twitter so useful and why it’s considered to be the next best thing after email. I also gave tips and tricks on how to use twitter effectively.
or you can download it in your favourite format: PDF, Powerpoint 2007, Powerpoint 97-2003. Please feel free to download it, forward it to your friends, especially the ones whom you want to convince to start using twitter.
The IndicThreads conference on Java technologies, which is an annual occurrence in Pune happened over the course of 3 days last week, and IndicThreads were gracious enough to invite me to attend the conference (sort of a press pass, so to speak), and although I wasn’t able to attend the whole conference, I did manage to squeeze in a couple of hours each day, and was very glad that I did, because I ended up with some really enriching sessions.
On the first day of the conference, the two big names of the tech industry in Pune, Ganesh Natarajan and Anand Deshpande gave keynote addresses. Ganesh, who is CEO of Zensar, and President of NASSCOM gave the NASSCOM view of the coming recession. His main thrust was that the Indian software / BPO industry will not be as badly affected by the recession as the rest of the world. He had a large number of graphs and figures to make the following points:
We had already been tightening the belt for almost an year now, so we are in much better shape to handle the recession than those who weren’t being so prudent
We are creating new products, tackling new verticals, and focusing on end-to-end service (and these claims were all backed by facts and figures), and this diversification and added value makes us resilient
And he spent a lot of time pointing out that to do even better, or primary focus needs to be the tier 2 / tier 3 cities, 43 of which have been identified by NASSCOM and whose developement will get some attention. Also, our tier 2 / tier 3 colleges are sub-par and a lot of work is needed to improve the quality of students graduating from there. NASSCOM has started a number of initiatives to tackle this problem.
Since this was a conference for Java techies, Anand Desphande, CEO of Persistent, presented his view of the broader context in which the Java programmers exist, and what are the things they need to think about (other than their code) to have a better long term view. Basically:
Multicore chips, and why programmers need to worry about them
Mobile Telephony: the desktop/laptop is no longer the primary target device for programmers. Think about the mobile users, and how what they want is different from the traditional PC users
Cloud and SaaS: is coming in a big way, and will change the way people use software. Also, it makes life easier for users, but much more difficult for programmers. So need to improve skills in these areas
Web 2.0 and Social Networking: these are exciting new fields with a lot of growth. They require a different kind of programming mindset.
Rich Internet Applications: Similar to above
Large Volumes of Diverse Data (including BI and analytics)
Open source is on the rise. As programmers, you must have a good understanding of various open source licenses
Gaming and Entertainment boom: Too many programmers think of only corporate world & green monitors etc. Think different. E.g. Gaming and entertainment are large markets and require a different mindset to come up with new ideas in these fields.
Green IT: Instead of worrying about speed and efficiency, for the first time, worrying about power consumption has started affecting programmers
Be a part of the community. Give back. Do open source. Join CSI ACM. IEEE. (and I would like to add contribute to PuneTech)
Anand also predicted that in the next 6 months, the Industry will see serious job cuts and salary cuts, and he things it is unavoidable. But pointed out that those who take trouble to keep themselves updated in their area of expertise, and go deep (instead of just doing “enough”) will not have a problem, and in fact will be best positioned to take advantage of the situation when the financial situation starts recovering after 6 to 9 months.
I missed the rest of day 1, but it has been covered in great detail by Dhananjay Nene. on his blog, as well as Varun Arora on the IndicThreads blog (part 1, part 2).
The highlight of day 2, and in fact the highlight of the whole week for me, was the presentation by DJ Patil, Chief Scientist of Linked-in. DJ Patil is in charge of all the data analysis that happens at Linked-in – basically the advanced guess they make like: “people who viewed this profile also viewed these other profiles”, and “people whom you might know” etc. He was not listed on the conference schedule – and was just passing through, and got invited to talk. He gave a great talk on an overview of how linked in works, their strategy for linked-in apps (the third-party apps that are integrated into the linked-in website). Again Dhananjay has already captured most of DJ’s important points on his blog, so I will not repeat those here. But I did have a very detailed conversation with DJ afterwards, and one of the things that came through was that they are looking seriously at India and wondering what they can / should do to get more Indians on linked-in. India already has about 4.8% of linked-in’s users. He was very open about trying to find out what are the things about linked-in that we don’t like, what are the things in linked-in that we would like to change, and what are the features we would like to see. If you have suggestions, send them over to him – he is dpatil on twitter.
The third day had a session on Grails by Harshad Oak, and if you are not familiar with Rails, or any of the other “programming by convention” schools of software, it is definitely something you should check out. It can reduce development times by orders of magnitude on things like building web applications and other things that are done over and over by programmers all over the world.
For other talks that happened, but which I missed, unfortunately, I haven’t been able to find any reports or blog posts giving details, but you can see the conference schedule to get an idea of what went on.
If you’ve been following the tech scene in Pune, you’d be aware of the tremendous success of PHPCamp Pune with over a 1000 registrants. One thing that quickly became clear during PHPCamp is the interest in having special interest groups for more specialized areas within PHP hacking – specifically Open Social, Drupal and Joomla!. To help you stay in touch, we asked Amit Kumar Singh, one of the primary movers behind PHPCamp, and behind the Joomla Users Group, India to give our readers an overview of Joomla! – what it is, and why is it so popular. This article is intentionally low-tech at our request – to give people just an quick overview of Joomla! If you want more details, especially technical deep dives, head over to Amit’s blog where he often has articles about Joomla!
Have you ever wondered how you can quickly build a website for yourself or your organization? If yes, then read on to find how you can do so.
What is Joomla!
Joomla! is a open source, content management system( CMS), written in PHP, licensed under GPL and managed by OSM Foundation .
Joomla is the English spelling of the Swahili word jumla meaning “all together” or “as a whole”. You can read more about history of Joomla at wikipedia.
Well, in one word, secret to build websites quickly and easily is Joomla!. It takes the pain out of building and maintaining websites. It is designed and build to make managing websites easier for a layman.
Where to use
It can be used to build
Personal Websites
Company’s Website
Small Business Websites
NGO Websites
Online magazines and publications websites
School and colleges Websites
This is basically list of things that can be done with Joomla out of box. Some of the core features of Joomla are
Article management
User registration and contacts
Themes
Search
Polling
Language support
Messaging
News Feeds and advertisement
If you need more, then you can easily extend Joomla to do lot more things and even use the framework to build some powerful applications. For example if you want to add additional fields to user registration form you can use community builder, if you want to put e-commerce shopping cart you can use vituemart, if you want to add forum you can use fireboard.
For me the best part of using Joomla is that it is very easy to customize and enhance. You can find extensions for your needs by simply looking in JED, just in case your need is really very unique then you can extend Joomla to suit your specific needs by writing simple components and modules.
If you get stuck while building something you can always find help from very active and helpful community members either at main Joomla Forum site or at Joomla User Group Pune.
Dhananjay Nene has just written a brilliant article in which he gives a detailed overview of multi-core architectures for computer CPUs – why they came about, how they work, and why you should care. Yesterday, Anand Deshpande, CEO of Persistent Systems, while speaking at the IndicThreads conference on Java Technologies exhorted all programmers to understand multi-core architectures and program to take advantage of the possibilities they provide. Dhananjay’s article is thus very timely for both, junior programmers who wish to understand why Anand was attaching so much importance to this issue, and what they need to do about it, and also for managers in infotech to understand how they need to deal with that issue.
Dhananjay sets the stage with this lovely analogy where he compares the CPU of your computer with superman (Kal-El) and then multi-core is explained thus:
One fine morning Kal’s dad Jor-El knocked on your door and announced that Kal had a built in limitation that he was approaching, and that instead of doubling his productivity every year, he shall start cloning himself once each year (even though they would collectively draw the same salary). Having been used to too much of the good life you immediately exclaimed – “But thats preposterous – One person with twice the standard skill set is far superior to 2 persons with a standard skill set, and many years down the line One person with 64 times the standard skill sets is far far far superior to 64 persons with a standard skill set”. Even as you said this you realised your reason for disappointment and consternation – the collective Kal family was not going to be doing any lesser work than expected but the responsibility of ensuring effective coordination across 64, 128 and 256 Kals now lay upon you the manager, and that you realised was a burden extremely onerous to imagine and even more so to carry. However productive the Kal family was, the weakest link in the productivity was now going to be you the project manager. That in a nutshell is the multicore challenge, and that in a nutshell is the burden that some of your developers shall need to carry in the years to come.
What is to be done? First is to understand which programs are well suited to take advantage of a multi-core architecture, and which ones:
if Kal had been working on one single super complex project, the task of dividing up the activities across his multiple siblings would be very onerous, but if Kal was working on a large number of small projects, it would be very easy to simply distribute the projects across the various Kal’s and the coordination and management effort would be unlikely to increase much.
Dhananjay goes into more detail on this and many other issues, that I am skimming over. For example:
Some environments lend themselves to easier multi threading / processing and some make it tough. Some may not support multi threading at all. So this will constrain some of your choices and the decisions you make. While Java and C and C++ all support multi threading, it is much easier to build multi threaded programs in Java than in C or C++. While Python supports multi threading building processes with more than a handful of threads will run into the GIL issue which will limit any further efficiency improvements by adding more threads. Almost all languages will work with multi processing scenarios.
Dhananjay is a Pune-based software Engineer with 17 years in the field. Passionate about software engineering, programming, design and architecture. For more info, check out his PuneTech wiki profile.
The Pune Linux Users Group (PLUG) had organized a code camp on Saturday, with the intention of getting a bunch of developers to get together and develop code, talk about code, answer each others’ coding questions on specific coding projects.
The following work was successfully done at the Code Camp –
Abhijit Bhopatkar – Added some functionality to TeamGit. He was very excited about it and shot off a long mail to the list as soon as he finished it, so I’m not going to spend any more words on that. Refer to his earlier mail on the list.
Guntapalli Karunakar – Started on something, but ended up spending most of the time in critical maintenance tasks of the Indlinux server!
Ashish Bhujbal and Amit Karpe – Worked on an HCL prototype notebook. Tried to resolve some issues with the X display rotation and calibration of the touchscreen. Solved both issues. Were trying to finish solving a problem with hibernation before going into hibernation themselves.
Aditya Godbole – Fixed 3 bugs in the lush-opencv package and added a utility function. One of the fix is already in the upstream cvs.
Of course, along with all this, we had a blast (which was the primary motive anyway).
Thanks to Manjusha for doing a bit of running around for organisation (in return for which we configured her ssh server 🙂 ). Thanks to Sudhanwa and Shantanoo for hanging around to give us company.
teamGit is a functional git gui written in qt, its ultimate aim is to add functionality
on top of git targeted at small closely nit teams.
After a succesfull codecamp session, I have tagged the repo with v0.0.8!!! You can now get the .deb from ubuntu intrepid ppa deb http://ppa.launchpad.net/bain-devslashzero/ubuntu. intrepid main
package name is teamgit.
The major feature add however is addition on **Advanced** menu.
This menu is constructed on the fly parsing output of ‘git help –all’ Then when you click on a menu item it issues git help , parses the manpage and presents its options in a guified form. It even display nice tooltips describing the option.
This is just a first stage of the planned feature. Ultimately this advanced menu will be just a ‘Admin’ feature. People will be able to save the selected options and parameters as ‘Receipies’ and can cook a nice receipes package particular to their needs/organisations.
The feature is not really complete yet, but you can issue simple commands using it. There _are_bugs_ but i couldn’t wait to showcase this nifty feature.
Photos of the event have been posted on flickr (thanks G Karunakar).
PLUG also holds monthly meetings on the first saturday of every month from 4pm to 6pm at SICSR. You can keep track of these and other tech events in Pune by following the PuneTech calendar, or by generally subscribing to the PuneTech feed.
When: Wednesday, November 19th, 2008, 6:30pm to 8:30pm Where: Dewang Mehta Auditorium, Persistent Systems, Senapati Bapat Road Entry: Free for CSI Members, Rs. 100 for others. Register here.
Details – Data Management for Business Intelligence
This lecture will cover the various issues in Data Management of Business Intelligence solutions: Why is Data management and data quality important, What is Data management, Components of Data management, Factors affecting Data management, Key Challenges in Data management, Data Quality, Data Quality process
It is not necessary to have attended the previous lecture.
For more information about other lectures in this series, and in general other tech events in Pune, see the PuneTech events calendar.
About the speaker – Ashwin Deokar
Ashwin is working as a business unit head with SAS R&D Pune. Heading the OnDemand Solution group. Ashwin has over 10 year of experience in ERP, DW, BI & Analytics across multiple domains like manufacturing, CPG, Retail, Banking & Insurance. He has been with SAS for 6 years under various roles like Project Manager, Senior Consultant, Business Unit head.
What: Seminar on Xen Virtual Machine architecture and server virtualization When: Monday, October 20, 2008 from 5:00pm – 7:00pm Where: Auditorium, Building “C”, Pune IT Park, Bhau Patil Road, Aundh Fees and Registration: This event is free for all. Register here
KQInfotech presents a seminar on the Xen Virtual Machines. We would present various server virtualization technologies in general. Xen virtual machine architecture will be presented in more detail. That would be followed by comparison of various virtual machine architectures.
This event is free for all.
You would need to register at http://mentor.kqinfotech.com to attend this seminar. Select Xen Virtual machine course from this page, it will take you a login page. Please select a login id for yourself and login. Please fill in the details.
Or you could just RSVP to alka at kqinfotech dot com
As usual, check the PuneTech Calendar for all happening tech events happening in Pune (which, incidentally, is a very happening place). Also, don’t forget to tell your friends about PuneTech, the … ahem … techies’ hub for bonding (as reported by the Pune Mirror yesterday).
This is going to be a very active weekend for tech activities in Pune. The big gorilla is of course, PHPCamp, the day long unconference for PHP enthusiasts on Saturday. With 700+ registrations from all over India (and indeed from other countries too), it promises to be a huge event even if just one third of the participants show up. Very impressive for a free event organized by volunteers in their free time. And if the enthusiasm seen at previous barcamps is any indication, the energy at this event will be awesome. This is a day long event at Persistent Systems near Null stop. Further event details are here.
If PHP is not your cup of tea, there are a couple of other events happening in parallel during the day. Dr. Neeran Karnik, a technical directory with Symantec Research Labs, Pune, will give a seminar on how to write good research papers at PICT. I’ve worked with Neeran for many years now, and he is good – both, as a researcher, and also as a speaker. If you have any intentions of doing research, or in general writing papers, I would say you should try to go for this one. Neeran has a PhD from the University of Minnesota, USA, and has worked with IBM Research Labs, Delhi, and Symantec Research Lab, Pune. He has been on numerous program committees of international academic conferences. He is also one of the original founders of CricInfo. This event is from 3pm to 5pm at PICT. Further details are here.
ThoughtWorks is organizing a Geek Night on Saturday afternoon, and the theme is Usability. Coming close on the heels of Pune OpenCoffee Club’s meetup on usability, this indicates that this very important field is finally getting the recognition it deserves in Pune. Abhijit Thosar, who has 20 years of experience in designing products based on emerging technologies will conduct the seminar. This event is from 2pm to 4pm at Thoughtworks, Yerwada. Further details are here.
Finally, September 20th is also Software Freedom day. But, wisely, the organizers have shifted the event to Sunday. This event will extol the virtues of free and open source software – like GNU/Linux, PHP – and is the place to go if you want to get started, or want help in any of these areas. Further details are here.
And Hemir Doshi, of IDG Ventures India, will be in Pune on Thursday and Friday, looking to meet early and early expansion stage technology and tech-enabled consumer companies. If you are interested in meeting hi, send him an email at hemir_doshi at idgvcindia dot com.
Stay in touch with all the interesting tech events happening in Pune, at the community-driven tech events calendar for Pune. Please note, it’s community driven. That means you. Please contribute. Add your events there.
And this is not confined to national boundaries. It is one of only two (as far as I know) Pune-based companies to be featured in TechCrunch (actually TechCrunchIT), one of the most influential tech blogs in the world (the other Pune company featured in TechCrunch is Pubmatic).
Why all this attention for Druvaa? Other than the fact that it has a very strong team that is executing quite well, I think two things stand out:
It is one of the few Indian product startups that are targeting the enterprise market. This is a very difficult market to break into, both, because of the risk averse nature of the customers, and the very long sales cycles.
Unlike many other startups (especially consumer oriented web-2.0 startups), Druvaa’s products require some seriously difficult technology.
The rest of this article talks about their technology.
Druvaa has two main products. Druvaa inSync allows enterprise desktop and laptop PCs to be backed up to a central server with over 90% savings in bandwidth and disk storage utilization. Druvaa Replicator allows replication of data from a production server to a secondary server near-synchronously and non-disruptively.
We now dig deeper into each of these products to give you a feel for the complex technology that goes into them. If you are not really interested in the technology, skip to the end of the article and come back tomorrow when we’ll be back to talking about google keyword searches and web-2.0 and other such things.
Druvaa Replicator
Overall schematic set-up for Druvaa Replicator
This is Druvaa’s first product, and is a good example of how something that seems simple to you and me can become insanely complicated when the customer is an enterprise. The problem seems rather simple: imagine an enterprise server that needs to be on, serving customer requests, all the time. If this server crashes for some reason, there needs to be a standby server that can immediately take over. This is the easy part. The problem is that the standby server needs to have a copy of the all the latest data, so that no data is lost (or at least very little data is lost). To do this, the replication software continuously copies all the latest updates of the data from the disks on the primary server side to the disks on the standby server side.
This is much harder than it seems. A simple implementation would simply ensure that every write of data that is done on the primary is also done on the standby storage at the same time (synchronously). This is unacceptable because each write would take unacceptably long and this would slow down the primary server too much.
If you are not doing synchronous updates, you need to start worrying about write order fidelity.
Write-order fidelity and file-system consistency
If a database writes a number of pages to the disk on your primary server, and if you have software that is replicating all these writes to a disk on a stand-by server, it is very important that the writes should be done on the stand-by in the same order in which they were done at the primary servers. This section explains why this is important, and also why doing this is difficult. If you know about this stuff already (database and file-system guys) or if you just don’t care about the technical details, skip to the next section.
Imagine a bank database. Account balances are stored as records in the database, which are ultimately stored on the disk. Imagine that I transfer Rs. 50,000 from Basant’s account to Navin’s account. Suppose Basant’s account had Rs. 3,00,000 before the transaction and Navin’s account had Rs. 1,00,000. So, during this transaction, the database software will end up doing two different writes to the disk:
write #1: Update Basant’s bank balance to 2,50,000
write #2: Update Navin’s bank balance to 1,50,000
Let us assume that Basant and Navin’s bank balances are stored on different locations on the disk (i.e. on different pages). This means that the above will be two different writes. If there is a power failure, after write #1, but before write #2, then the bank will have reduced Basant’s balance without increasing Navin’s balance. This is unacceptable. When the database server restarts when power is restored, it will have lost Rs. 50,000.
After write #1, the database (and the file-system) is said to be in an inconsistent state. After write #2, consistency is restored.
It is always possible that at the time of a power failure, a database might be inconsistent. This cannot be prevented, but it can be cured. For this, databases typically do something called write-ahead-logging. In this, the database first writes a “log entry” indicating what updates it is going to do as part of the current transaction. And only after the log entry is written does it do the actual updates. Now the sequence of updates is this:
write #0: Write this log entry “Update Basant’s balance to Rs. 2,50,000; update Navin’s balance to Rs. 1,50,000” to the logging section of the disk
write #1: Update Basant’s bank balance to 2,50,000
write #2: Update Navin’s bank balance to 1,50,000
Now if the power failure occurs between writes #0 and #1 or between #1 and #2, then the database has enough information to fix things later. When it restarts, before the database becomes active, it first reads the logging section of the disk and goes and checks whether all the updates that where claimed in the logs have actually happened. In this case, after reading the log entry, it needs to check whether Basant’s balance is actually 2,50,000 and Navin’s balance is actually 1,50,000. If they are not, the database is inconsisstent, but it has enough information to restore consistency. The recovery procedure consists of simply going ahead and making those updates. After these updates, the database can continue with regular operations.
(Note: This is a huge simplification of what really happens, and has some inaccuracies – the intention here is to give you a feel for what is going on, not a course lecture on database theory. Database people, please don’t write to me about the errors in the above – I already know; I have a Ph.D. in this area.)
Note that in the above scheme the order in which writes happen is very important. Specifically, write #0 must happen before #1 and #2. If for some reason write #1 happens before write #0 we can lose money again. Just imagine a power failure after write #1 but before write #0. On the other hand, it doesn’t really matter whether write #1 happens before write #2 or the other way around. The mathematically inclined will notice that this is a partial order.
Now if there is replication software that is replicating all the writes from the primary to the secondary, it needs to ensure that the writes happen in the same order. Otherwise the database on the stand-by server will be inconsistent, and can result in problems if suddenly the stand-by needs to take over as the main database. (Strictly speaking, we just need to ensure that the partial order is respected. So we can do the writes in this order: #0, #2, #1 and things will be fine. But #2, #0, #1 could lead to an inconsistent database.)
Replication software that ensures this is said to maintain write order fidelity. A large enterprise that runs mission critical databases (and other similar software) will not accept any replication software that does not maintain write order fidelity.
Why is write-order fidelity difficult?
I can here you muttering, “Ok, fine! Do the writes in the same order. Got it. What’s the big deal?” Turns out that maintaining write-order fidelity is easier said than done. Imagine the your database server has multiple CPUs. The different writes are being done by different CPUs. And the different CPUs have different clocks, so that the timestamps used by them are not nessarily in sync. Multiple CPUs is now the default in server class machines. Further imagine that the “logging section” of the database is actually stored on a different disk. For reasons beyond the scope of this article, this is the recommended practice. So, the situation is that different CPUs are writing to different disks, and the poor replication software has to figure out what order this was done in. It gets even worse when you realize that the disks are not simple disks, but complex disk arrays that have a whole lot of intelligence of their own (and hence might not write in the order you specified), and that there is a volume manager layer on the disk (which can be doing striping and RAID and other fancy tricks) and a file-system layer on top of the volume manager layer that is doing buffering of the writes, and you begin to get an idea of why this is not easy.
Naive solutions to this problem, like using locks to serialize the writes, result in unacceptable degradation of performance.
Druvaa Replicator has patent-pending technology in this area, where they are able to automatically figure out the partial order of the writes made at the primary, without significantly increasing the overheads. In this article, I’ve just focused on one aspect of Druvaa Replicator, just to give an idea of why this is so difficult to build. To get a more complete picture of the technology in it, see this white paper.
Druvaa inSync
Druvaa inSync is a solution that allows desktops/laptops in an enterprise to be backed up to a central server. (The central server is also in the enterprise; imagine the central server being in the head office, and the desktops/laptops spread out over a number of satellite offices across the country.) The key features of inSync are:
The amount of data being sent from the laptop to the backup server is greatly reduced (often by over 90%) compared to standard backup solutions. This results in much faster backups and lower consumption of expensive WAN bandwidth.
It stores all copies of the data, and hence allows timeline based recovery. You can recover any version of any document as it existed at any point of time in the past. Imagine you plugged in your friend’s USB drive at 2:30pm, and that resulted in a virus that totally screwed up your system. Simply uses inSync to restore your system to the state that existed at 2:29pm and you are done. This is possible because Druvaa backs up your data continuously and automatically. This is far better than having to restore from last night’s backup and losing all data from this morning.
It intelligently senses the kind of network connection that exists between the laptop and the backup server, and will correspondingly throttle its own usage of the network (possibly based on customer policies) to ensure that it does not interfere with the customer’s YouTube video browsing habits.
Data de-duplication
Overview of Druvaa inSync. 1. Fingerprints computed on laptop sent to backup server. 2. Backup server responds with information about which parts are non-duplicate. 3. Non-duplicate parts compressed, encrypted and sent.
Let’s dig a little deeper into the claim of 90% reduction of data transfer. The basic technology behind this is called data de-duplication. Imagine an enterprise with 10 employees. All their laptops have been backed up to a single central server. At this point, data de-duplication software can realize that there is a lot of data that has been duplicated across the different backups. i.e. the 10 different backups of contain a lot of files that are common. Most of the files in the C:\WINDOWS directory. All those large powerpoint documents that got mail-forwarded around the office. In such cases, the de-duplication software can save diskspace by keeping just one copy of the file and deleting all the other copies. In place of the deleted copies, it can store a shortcut indicating that if this user tries to restore this file, it should be fetched from the other backup and then restored.
Data de-duplication doesn’t have to be at the level of whole files. Imagine a long and complex document you created and sent to your boss. Your boss simply changed the first three lines and saved it into a document with a different name. These files have different names, and different contents, but most of the data (other than the first few lines) is the same. De-duplication software can detect such copies of the data too, and are smart enough to store only one copy of this document in the first backup, and just the differences in the second backup.
The way to detect duplicates is through a mechanism called document fingerprinting. Each document is broken up into smaller chunks. (How do determine what constitutes one chunk is an advanced topic beyond the scope of this article.) Now, a short “fingerprint” is created for each chunk. A fingerprint is a short string (e.g. 16 bytes) that is uniquely determined by the contents of the entire chunk. The computation of a fingerprint is done in such a way that if even a single byte of the chunk is changed, the fingerprint changes. (It’s something like a checksum, but a little more complicated to ensure that two different chunks cannot accidently have the same checksum.)
All the fingerprints of all the chunks are then stored in a database. Now everytime a new document is encountered, it is broken up into chunks, fingerprints computed and these fingerprints are looked up in the database of fingerprints. If a fingerprint is found in the database, then we know that this particular chunk already exists somewhere in one of the backups, and the database will tell us the location of the chunk. Now this chunk in the new file can be replaced by a shortcut to the old chunk. Rinse. Repeat. And we get 90% savings of disk space. The interested reader is encouraged to google Rabin fingerprinting, shingling, Rsync for hours of fascinating algorithms in this area. Before you know it, you’ll be trying to figure out how to use these techniques to find who is plagiarising your blog content on the internet.
Back to Druvaa inSync. inSync does fingerprinting at the laptop itself, before the data is sent to the central server. So, it is able to detect duplicate content before it gets sent over the slow and expensive net connection and consumes time and bandwidth. This is in contrast to most other systems that do de-duplication as a post-processing step at the server. At a Fortune 500 customer site, inSync was able reduce the backup time from 30 minutes to 4 minutes, and the disk space required on the server went down from 7TB to 680GB. (source.)
Again, this was just one example used to give an idea of the complexities involved in building inSync. For more information on other distinguishinging features, check out the inSync product overview page.
Have questions about the technology, or about Druvaa in general? Ask them in the comments section below (or email me). I’m sure Milind/Jaspreet will be happy to answer them.
Also, this long, tech-heavy article was an experiment. Did you like it? Was it too long? Too technical? Do you want more articles like this, or less? Please let me know.
Business intelligence and analytics company SAS announced a few days back that it is acquiring revenue optimization company IDeaS. Both, SAS and IDeaS have major development centers in Pune. This article gives an overview of the software that IDeaS sells.
I always found airfares very confusing and frustrating (more so in the US than in India). A roundtrip sometimes costs less than a one-way ticket. Saturday night stayovers cost less. The same flight can cost $900 or $90 (and those two guys might end up sitting on adjacent seats). The reason we see such bizarre behavior is because of a fascinating field of economics called Revenue Optimization.
IDeaS software (which has a major development center in Pune) provides software and services that help companies (for example hotels) to determine what is the best price to charge customers so as to maximize revenue. The technology called pricing and revenue optimization – also called Revenue Management (RM) – focuses on how an organization should set and update their pricing and product availability across its various sales channels in order to maximize profitability.
First it is necessary to understand some basic economic concepts.
Market Segmentation
If you don’t really know what market segmentation is, then I would highly recommend that you read Joel Spolsky‘s article Camels and Rubber Duckies. It is a must read – especially for engineers who haven’t had the benefit of a commerce/economics education. (And also for commerce grads who did not pay attention in class.)
Here is the very basic idea of market segmentation
Poor Programmer want to take a 6am Bombay-Delhi flight to attend a friend’s wedding. He is willing to pay up to Rs. 4000 for the flight. If the price is higher, he will try alternatives like a late-night flight, or going by train.
On another occassion, the same Poor Programmer is being sent to Delhi for a conference by his company. In this case, he doesn’t care if the price is Rs. 8000, he will insist on going by the 6am flight.
If the airline company charges Rs. 8000 to all customers, a lot of its seats will go empty, and it is losing out on potential revenue. If it charges Rs. 4000 for all seats, then all seats will fill up quickly, but it is leaving money on the table since there were obviously some customers who were willing to pay much more.
The ideal situation is to charge each customer how much she is willing to pay, but that involves having a salesperson involved in every sale, which has its own share of problems. Better is to partition your customers into two or three segments and charge a different price for each.
Unfortunately, customers do not come with a label on their forehead indicating the maximum amount they are willing to pay. And, even the guy paying Rs. 8000 feels cheated if he finds out that someone else paid Rs. 4000 for the same thing. This is where the real creativity of the marketers comes in.
The person in the Rs. 4000 market segment (leisure travel) books well in advance and usually stays over the weekend. The person in the Rs. 8000 market segment (business travel) books just a few days before the flight, and wants to be back home to his family for the weekend. This is why the airlines have low prices if you book in advance, and why airlines (at least in the US) have lower prices in case of a weekend stayover.
This also keeps the rich customer from feeling cheated. “Why did I pay more for the same seat?” If you try saying “Because you are rich,” he is going to blow his top. But instead if you say, “Sir, that’s because this seat is not staying over the weekend,” the customer feels less cheated. Seriously. That’s how psychology works.
Exercise for the motivated reader – figure out how supermarket discount coupons work on the same principle.
Forecasting demand
This is the key strength of IDeaS revenue optimization software.
You need to guess how many customers you will get in each market segment and then allocate your reservations accordingly. Here is an excerpt from their excellent white-paper on Revenue Management:
The objective of revenue management is to allocate inventory among price levels/market segments to maximize total expected revenue or profits in the face of uncertain levels of demand for your service.
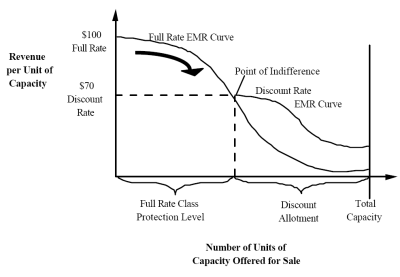
If we reserve a unit of capacity (an airline seat or a hotel room or 30 seconds of television advertising time) for the exclusive use of a potential customer who has a 70 percent probability of wanting it and is in a market segment with a price of $100 per unit, then the expected revenue for that unit is $70 ($100 x 70%). Faced with this situation 10 times, we would expect that 7 times the customer would appear and pay us $100 and 3 times he would fail to materialize and we would get nothing. We would collect a total of $700 for the 10 units of capacity or an average of $70 per unit.
Suppose another customer appeared and offered us $60 for the unit, in cash, on the spot. Should we accept his offer? No, because as long as we are able to keep a long-term perspective, we know that a 100 percent probability of getting $60 gives us expected revenue of only $60. Over 10 occurrences we would only get $600 following the “bird in the hand” strategy.
Now, what if instead the customer in front of us was offering $80 cash for the unit. Is this offer acceptable to us? Yes; because his expected revenue (100% x $80 = $80) is greater than that of the potential passenger “in the bush”. Over 10 occurrences, we would get $800 in this situation or $80 per unit.
If the person offers exactly $70 cash we would be indifferent about selling him the unit because the expected revenue from him is equal to that of the potential customer (100% x $70 = 70% x $100 = $70). The bottom line is that $70 is the lowest price that we should accept from a customer standing in front of us. If someone offers us more than $70, we sell, otherwise we do not. This is one of the key concepts of Revenue Management:
We should never sell a unit of capacity for less than we expect to receive for it from another customer, but if we can get more for it, the extra revenue goes right to the bottom line.
What would have happened in this case if we had incorrectly assumed that we “knew” certainty that the potential $100 customer would show up (after all, he usually does!). We would have turned away the guy who was willing to pay us $80 per unit and at the end of 10 occurrences, we would have $700 instead of $800.
Thus we can see that by either ignoring uncertainty and assuming that what usually happens will always happen, or by always taking “the bird in the hand” we are afraid to acknowledge and manage everyday risk and uncertainty as a normal part of doing business, we lose money.
The Expected Marginal Revenue
The previous section gave an idea of the basic principle to be used in revenue maximization. In practice, the probability associated with a particular market segment is not fixed, but varies with time and with the number of units available for sale.
One of the key principles of revenue management is that as the level of available capacity increases, the marginal expected revenue from each additional unit of capacity declines. If you offer only one unit of capacity for sale the probability of selling it is very high and it is very unlikely that you will have to offer a discount in order to sell it. Thus, the expected revenue estimate for that first unit will be quite high. However, with each additional unit of capacity that you offer for sale, the probability that it will be sold to a customer goes down a little (and the pressure to discount it goes up) until you reach the point where you are offering so much capacity that the probability of selling the last additional unit is close to zero, even if you practically give it away. At this point the expected revenue estimate for that seat is close to zero ($100 x 0% = $0). Economists call this phenomenon the Expected Marginal Revenue Curve, which looks something like this:
There is an EMR curve like this for each market segment. Note that it will also vary based on time of the year, day of the week (i.e. whether the flight is on a weekend or not), and a whole bunch of other parameters. By looking at historical data, and correlating it with all the interesting parameters, Revenue Management software can estimate the EMR curve for each of your market segments.
Now, for any given sale, first plot the EMR curves for the different market segments you have created, and find the point at which the rich guys’ curve crosses and goes under the poor guys’ curve. See the number of units (on the x-axis) for this crossover point and sell to the poor guy only if the number of units currently remaining is less than this.
Applications
Revenue Optimization of this type is applicable whenever you are in a business that has the following characteristics:
Perishable inventory (seats become useless after the flight takes off)
Relatively fixed capacity (can’t add hotel rooms to deal with extra weekend load)
High fixed costs, low variable costs (you’ve got to pay the air-hostess whether the flight is full or empty)
Advance reservations
Time variable demand
Appropriate cost and pricing structure
Segmentable markets
Due to this, almost all major Hotel, Car Rental Agencies, Cruise Lines and Passenger Railroad firms have, or are developing, revenue management systems. Other industries that appear ripe for the application of revenue management concepts include Golf Courses, Freight Transportation, Health Care, Utilities, Television Broadcast, Spa Resorts, Advertising, Telecommunications, Ticketing, Restaurants and Web Conferencing.
Revenue Management software helps you with handling seasonal demand and peak/off-peak pricing, determining how much to overbook, what rates to charge in each market segment. It is also useful in evaluating corporate contracts and market promotions. And there are a whole bunch of other issues that make the field much more complicated, and much more interesting. So, if you found this article interesting, you must check out IDeaS white-paper on Revenue Management – it is very well written, and has many more fascinating insights into this field.


![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=413e2d5b-e6da-40a7-88f6-1590b7701374)





![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_b.png?x-id=f634e44f-76a2-4e8c-a355-a6ec0473e333)
{kind=link}